概述:最近在公司的服务器上里进行环境部署,需要使用GPU进行深度学习,发现之前使用docker部署的环境直接安装nvidia驱动会不停的产生错误,折腾了一整天,终于成功的在docker镜像中成功部署显卡驱动,使用pytorch成功调用显卡进行深度学习训练,本篇博客对整个docker-torch-gpu部署过程进行记录。

docker中调用GPU
关键点1——使用已经部署好GPU的image
这里首先给想要在docker中使用GPU的朋友一个忠告,尽量不要使用已经部署好其他环境的docker来安装GPU驱动,而是直接去找到包含了GPU驱动和cuda的image来安装其他需要的包。
首先在docker hub上找到pytorch官方发布的images项目,点击进入。
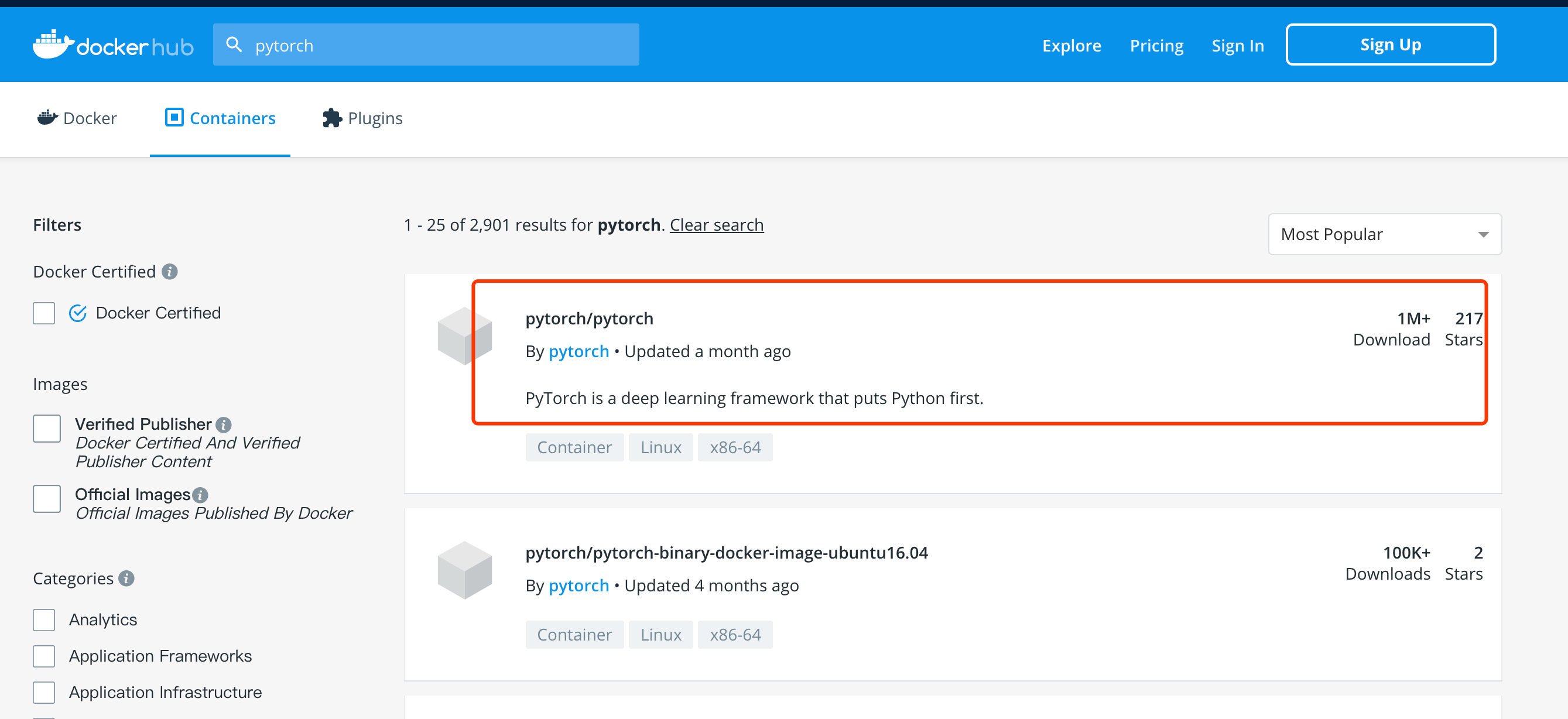
然后点击Tags按钮在其中找到对应的版本。
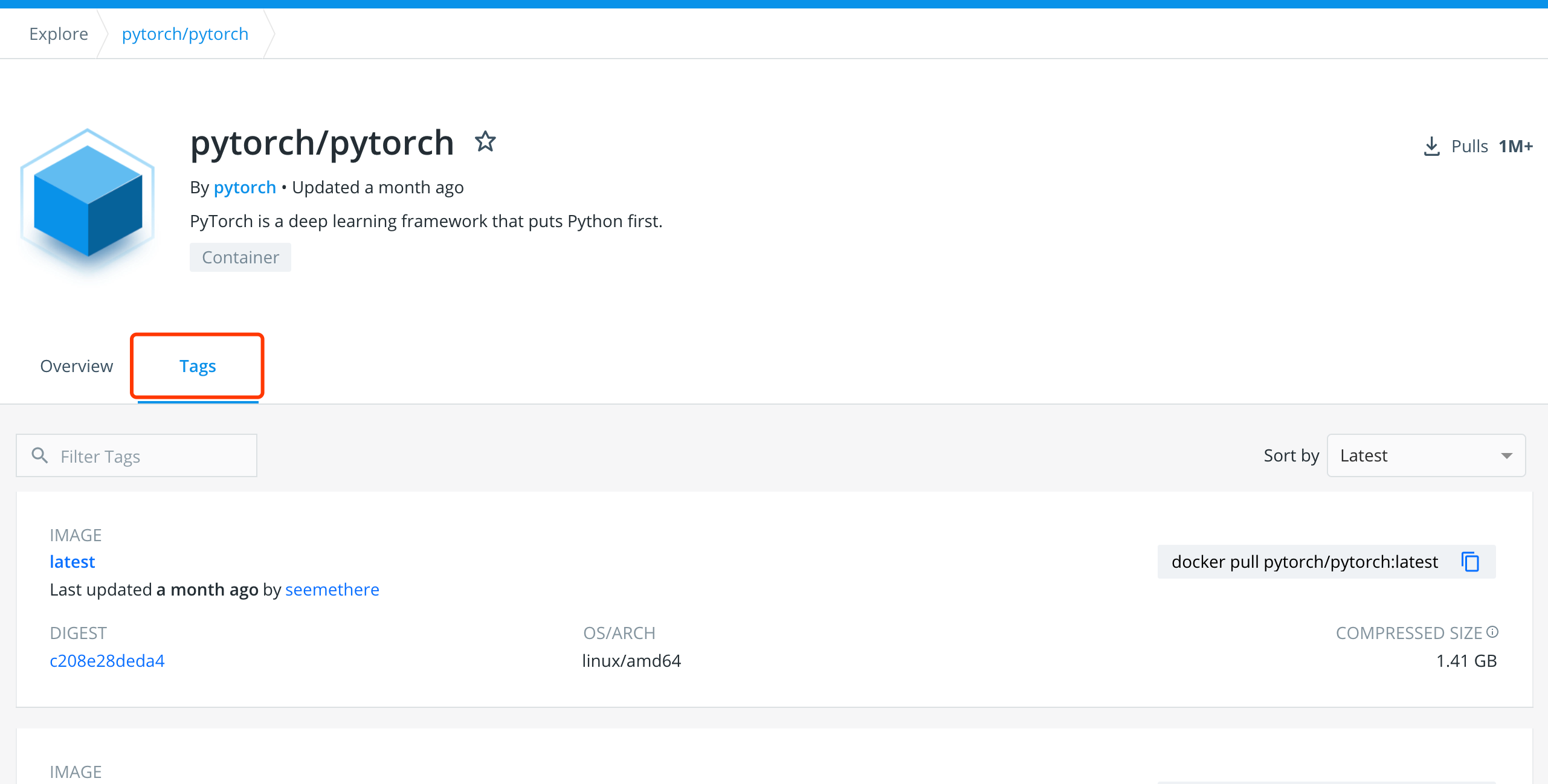
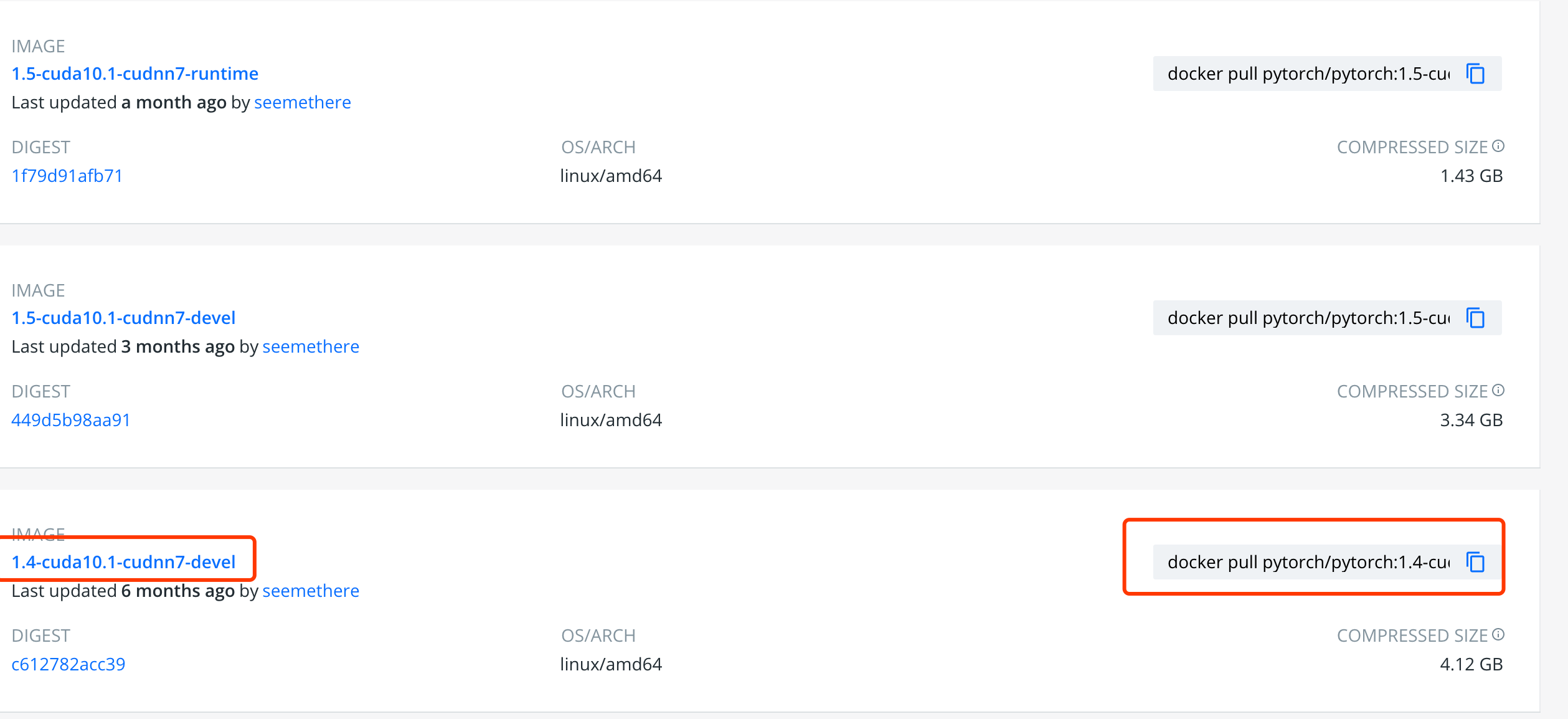
按照对应版本的image后面显示的方式进行下拉镜像。
1 | docker pull pytorch/pytorch:1.4-cuda10.1-cudnn7-devel |
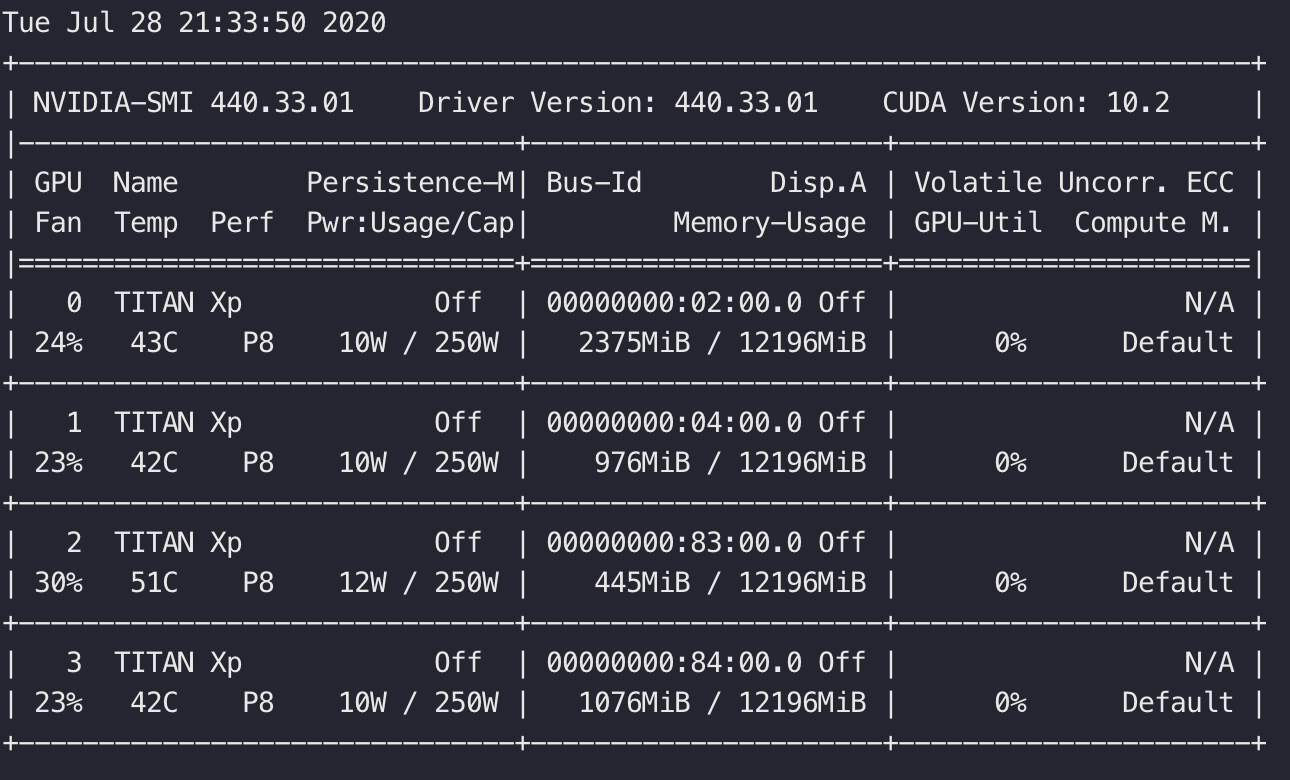
对于需要的cuda版本不清楚的,可以再docker外面使用nvidia-smi查看宿主机所使用的cuda版本进行确定。
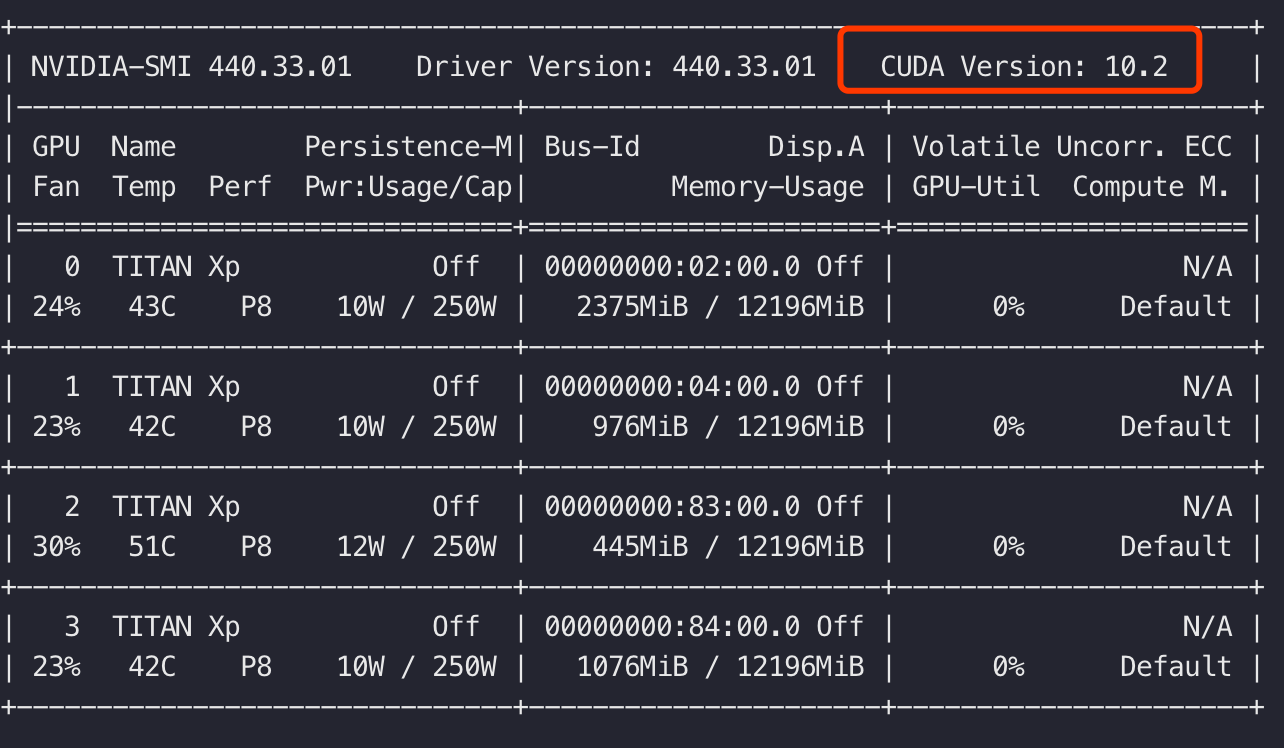
注意:上面的截图是另一台机器的截图,按照上面的截图前面pull的镜像也cuda版本应该为10.2,而不是10.1
关键点2——使用runtime属性指定nvidia
使用docker进行GPU利用的第二个关键点就是使用部署好GPU环境的image生成container时,要使用附加参数—runtime指定使用nvidia驱动,创建方式如下:
1 | sudo docker run --runtime=nvidia \ # |
使用该命令成功创建并进入docker后,采用nvida-smi命令查看是否GPU可用。出现下面界面证明GPU可用。