概述:强化学习经典算法QLearning算法从算法过程、伪代码、代码角度进行介绍。
Q-Learning
Q-Learning 是一个强化学习中一个很经典的算法,其出发点很简单,就是用一张表存储在各个状态下执行各种动作能够带来的 reward,如下表表示了有两个状态 s1,s2,每个状态下有两个动作 a1,,a2, 表格里面的值表示 reward
| - | a1 | a2 |
|---|---|---|
| s1 | -1 | 2 |
| s2 | -5 | 2 |
这个表示实际上就叫做 Q-Table,里面的每个值定义为 Q(s,a), 表示在状态 s 下执行动作 a 所获取的reward,那么选择的时候可以采用一个贪婪的做法,即选择价值最大的那个动作去执行。
算法过程
Q-Learning算法的核心问题就是Q-Table的初始化与更新问题,首先就是就是 Q-Table 要如何获取?答案是随机初始化,然后通过不断执行动作获取环境的反馈并通过算法更新 Q-Table。下面重点讲如何通过算法更新 Q-Table。
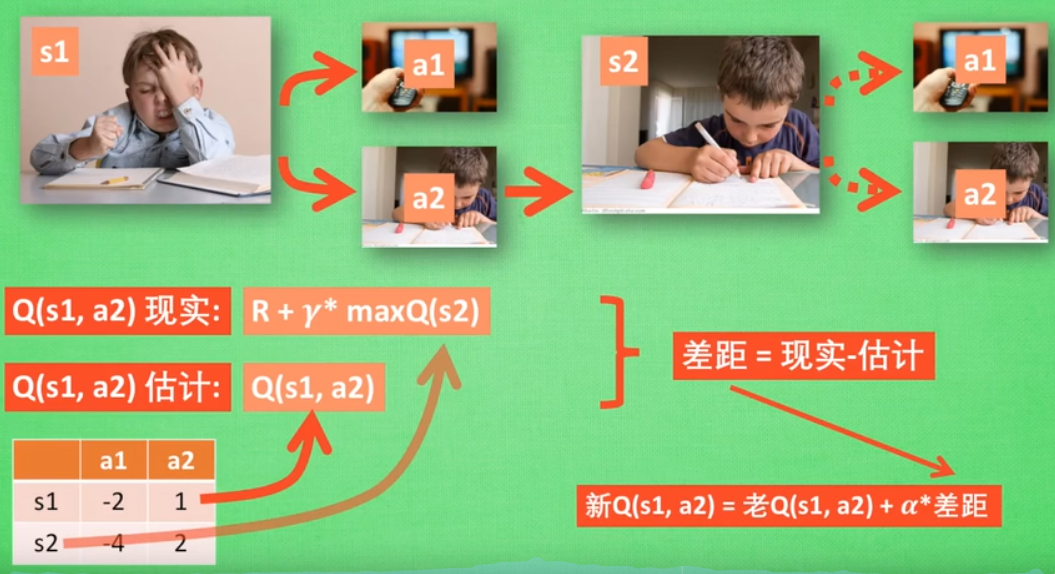
当我们处于某个状态 s 时,根据 Q-Table 的值选择的动作 a, 那么从表格获取的 reward 为 Q(s,a),此时的 reward 并不是我们真正的获取的 reward,而是预期获取的 reward:
那么真正的 reward 在哪?我们知道执行了动作 a 状态从s转移到了 s′ 时,能够获取一个即时的 reward(记为r), 但是除了即时的 reward,还要考虑所转移到的状态 s′ 对未来期望的reward,因此真实的 reward (记为 Q′(s,a)由两部分组成:即时的 reward 和未来期望的 reward,且未来的 reward 往往是不确定的,因此需要加个折扣因子 γ,则真实的 reward 表示如下
γ 的值一般设置为 0 到 1 之间,设为0时表示只关心即时回报,设为 1 时表示未来的期望回报跟即时回报一样重要。
r:立即奖励,如果没有获得立即reward则为0
Q(s’):表示当采取行为a后状态由s转为s’后,能够得到的最大reward值,用来表示将来的期望reward。
有了真实的 reward 和预期获取的 reward,可以很自然地想到用 supervised learning那一套,求两者的误差然后进行更新,在 Q-learning 中也是这么干的,更新的值则是原来的 Q(s, a),更新规则如下:
更新规则跟梯度下降非常相似,这里的 α 可理解为学习率。
Q-Learning 中还存在着探索与利用(Exploration and Exploition)的问题, 大致的意思就是不要每次都遵循着当前看起来是最好的方案,而是会选择一些当前看起来不是最优的策略,这样也许会更快探索出更优的策略。Exploration and Exploition 的做法很多,Q-Learning 采用了最简单的 ϵ-greedy, 就是每次有 ϵ的概率是选择当前 Q-Table 里面值最大的action的,1 - ϵ的概率是随机选择策略的。
伪代码
Q-Learning 算法的流程如下,图片摘自这里

上面的流程中的 Q 现实 就是上面说的 Q′(s,a), Q 估计就是上面说的 Q(s,a)。
代码
下面的 python 代码演示了更新通过 Q-Table 的算法, 参考了这个 repo 上的代码,初始化主要是设定一些参数,并建立 Q-Table, choose_action 是根据当前的状态 observation,并以 ϵ-greedy 的策略选择当前的动作; learn 则是更新当前的 Q-Table,check_state_exist 则是检查当前的状态是否已经存在 Q-Table 中,若不存在要在 Q-Table 中创建相应的行。
1 | import numpy as np |
参考文献
- xxx
- xxx