概述:首页描述
框架结构
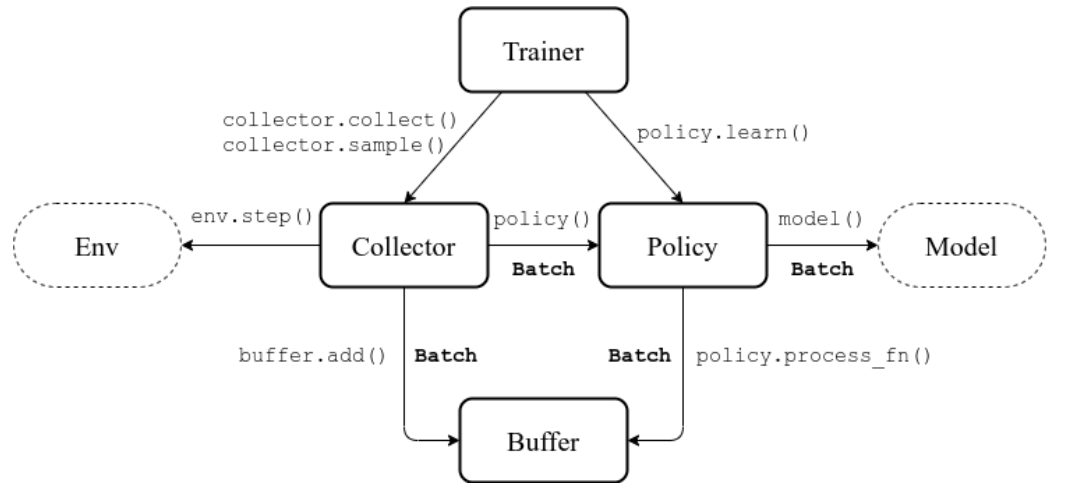
Buffer
在tianshou中的Buffer本质上就是传统方法中即Memory,用于存储最近学习过程中一定数量的信息,其中的信息包括:
obs时刻的观测值;
actrewdoneobs_next时刻的观测值;
infopolicy
Policy
Policy类设定了设定了RL算法进行训练时的学习策略,包括行为选择、记忆存储(存储到Buffer中)、目标网络参数如何进行更新等,主要功能:
_init\_(): 策略初始化
forward(): 给定状态观测值,计算出要采取的行动action
process_fn(): 在获取训练数据之前与buffer进行交互,
learn(): 使用一个batch的数据进行策略更新
post_process_fn():使用一个Batch的数据进行Buffer的更新(比如更新PER);update():最主要的接口。这个update函数先是从buffer采样出一个batch,然后调用process_fn预处理,然后learn更新策略,然后 post_process_fn完成一次迭代:process_fn -> learn -> post_process_fn。
1 | policy = ts.policy.DQNPolicy( |
Collector
Collector主要负责policy和env之间的交互和数据存储,它能够指定policy和env交互多少个step或eplison,并把该过程产生的数据存储到Buffer中。
max_epoch:最大允许的训练轮数,有可能没训练完这么多轮就会停止(因为满足了stop_fn的条件)step_per_epoch:每个epoch要更新多少次策略网络collect_per_step:每次更新前要收集多少帧与环境的交互数据。上面的代码参数意思是,每收集10帧进行一次网络更新episode_per_test:每次测试的时候花几个rollout进行测试batch_size:每次策略计算的时候批量处理多少数据train_fn:在每个epoch训练之前被调用的函数,输入的是当前第几轮epoch和当前用于训练的env一共step了多少次。上面的代码意味着,在每次训练前将epsilon设置成0.1test_fn:在每个epoch测试之前被调用的函数,输入的是当前第几轮epoch和当前用于训练的env一共step了多少次。上面的代码意味着,在每次测试前将epsilon设置成0.05
stop_fn:停止条件,输入是当前平均总奖励回报(the average undiscounted returns),返回是否要停止训练
writer:天授支持 TensorBoard,可以像下面这样初始化:
2
3
writer = SummaryWriter('log/dqn')
返回结果为字典:
1 | { |
Trainer
标准训练器使用
自定义训练训练器
在tianshou中Trainer只使用了很少的封装,用户可以很容易的进行自定义自己的训练策略,例如:
1 | # 在正式训练前先收集5000帧数据 |
DQNPolicy(
model :DQN组成的基础模型
optim:模型优化算法
discount_factor=0.9, 奖励衰减率
estimation_step=3 :更新的窗口
target_update_freq:记忆体更新频率,也就是记忆体的大小
)
参考文献
- xxx
- xxx