概述:强化学习用于恶意代码混淆的比较早期、经典的论文。
基本情况
攻击目标:静态可执行文件检测引擎
方法:强化学习,通过设计一些类的混淆策略,让代理与检测引擎进行一些列的交互以后,RL模型可以学习到对于任何给定的模型都给出可以绕过静态检测引擎的检测。
模型输出:可以逃逸静态模型(黑盒测试)检测的恶意软件
链接:https://arxiv.org/pdf/1801.08917.pdf
开源代码:https://github.com/endgameinc/gym- malware
创新点:
- 能够使用Rl对静态文件检测引擎进行自动绕过的模型
- 提供了一个gym_malware环境,用来读者可以使用自己的RL模型进行静态检测引擎绕过尝试
- 直接攻击能够提升33%的成功率
具体实现细节
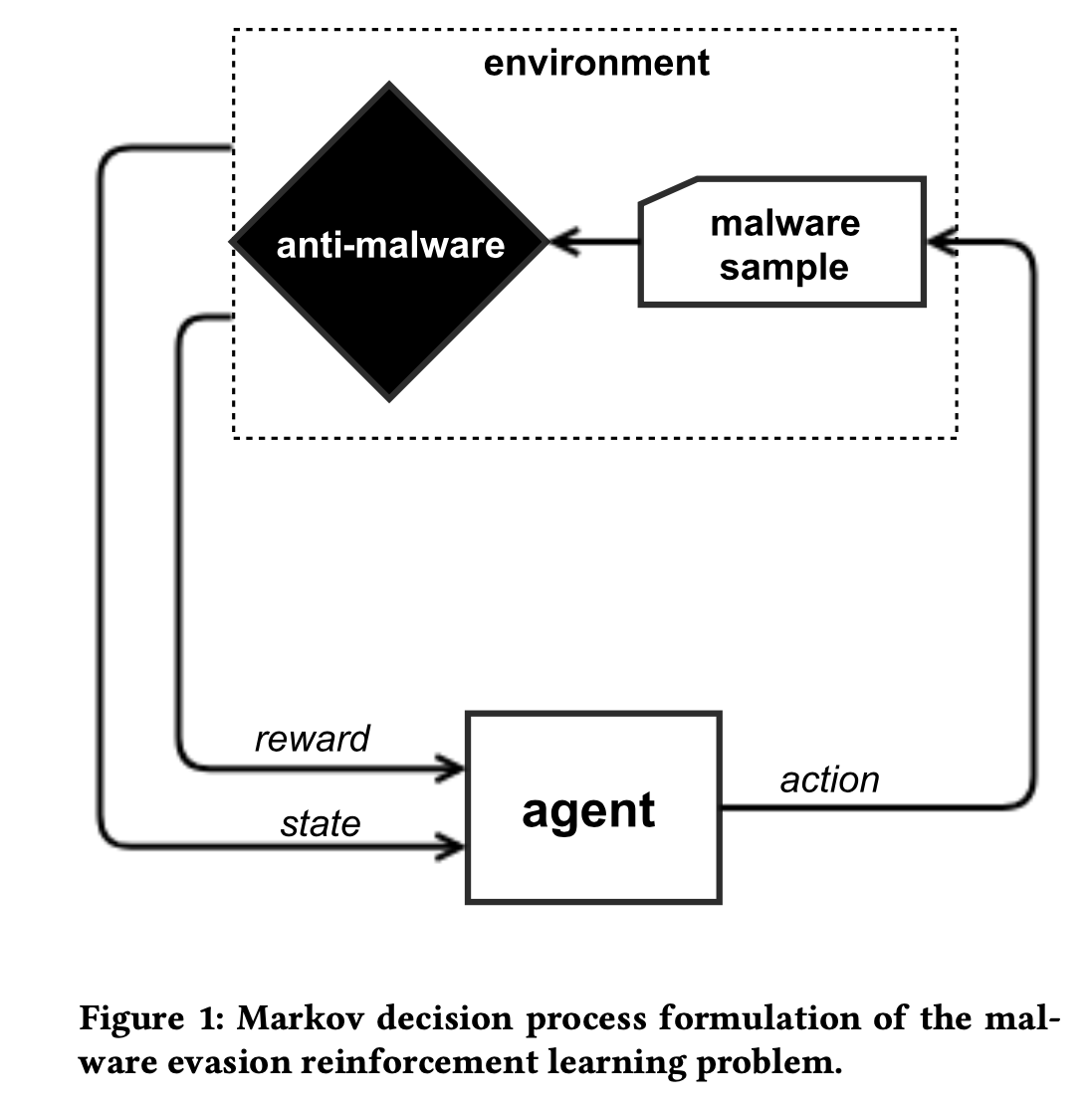
Enviroment
本文使用自己训练的GBDT恶意软件静态检测模型作为受测模型,模型2350维特征,包括:
- PE头 metadata
- Section metadata: section name,size and characteristics
- 导入导出表的 metadata
- 人类可读字符串数量(e.g. file paths, URLs,and registry key names)
- 字节直方图
- 2维字节熵直方图
该模型使用10w正常软件与恶意软件进行训练,在输出阈值为0.9的前提下,在测试集上可以达到1%的误报率与90%的检出率。
Action空间
收集了各种能够在不改变PE文件正常执行功能的前提下改变PE文件格式的混淆操作,作为Actions空间。具体包括:
- 向从未使用的导入地指标添加功能
- 操纵现有Section 名称
- 创建新Section(不会被使用到)
- 在Section尾部的额外空间之间bytes
- 创建新的入口点,新的入口点将跳到原来的入口点
- 删除签名者信息
- 操纵调试信息
- 打包或者解包文件
- 修改或者破坏头部和校验
- 追加Bytes到PE文件的尾部
实验设置
强化学习算法:ACER
最大变异次数:10次
奖励:每次成功绕过奖励为10
流程:
每个round随机选择一个样本开始进行编译,当样本编译次数达到十次或者恶意样本能够成功绕过检测模型,则结束当前round,模型训练过程之允许采用50000次变异。
实验结果
整体上使用强化学习的方式进行变异方式的选择成功率要比随即进行样本变异的成功率要高
注意:这里成功率是指在10次变异操作内完成检测模型绕过

- 使用强化学习方式绕过检测使用变异的次数比随机变异次数样更少
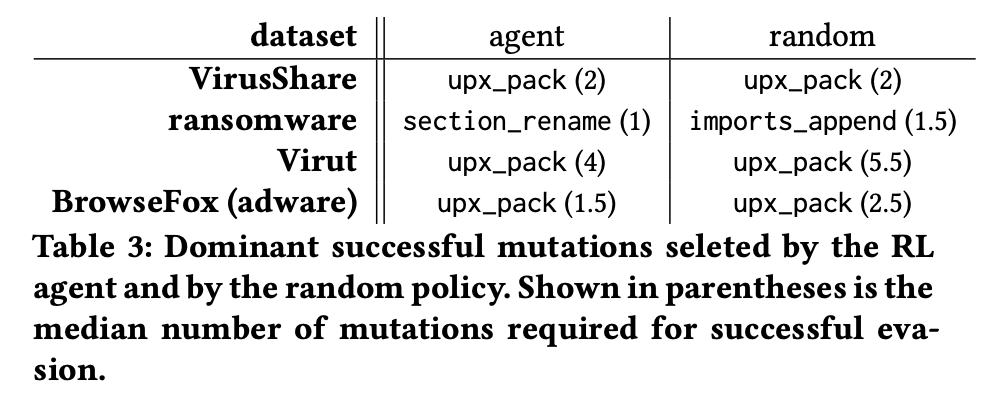
使用简单的样本进行恶意软件混淆强化学习,是很有可能将模型迁移到商业检测模型的绕过的
在这里存在一个疑问,这里使用随机混淆使Virustotal检测的检出样本数量比强化学习agent变异后的样本检出率更低,那为什么还需要使用强化学习进行绕过呢?这里姑且认为是因为强化学习能够使用更少的尝试次数进行绕过,这里只是为了证明强化学习混淆的可迁移性。
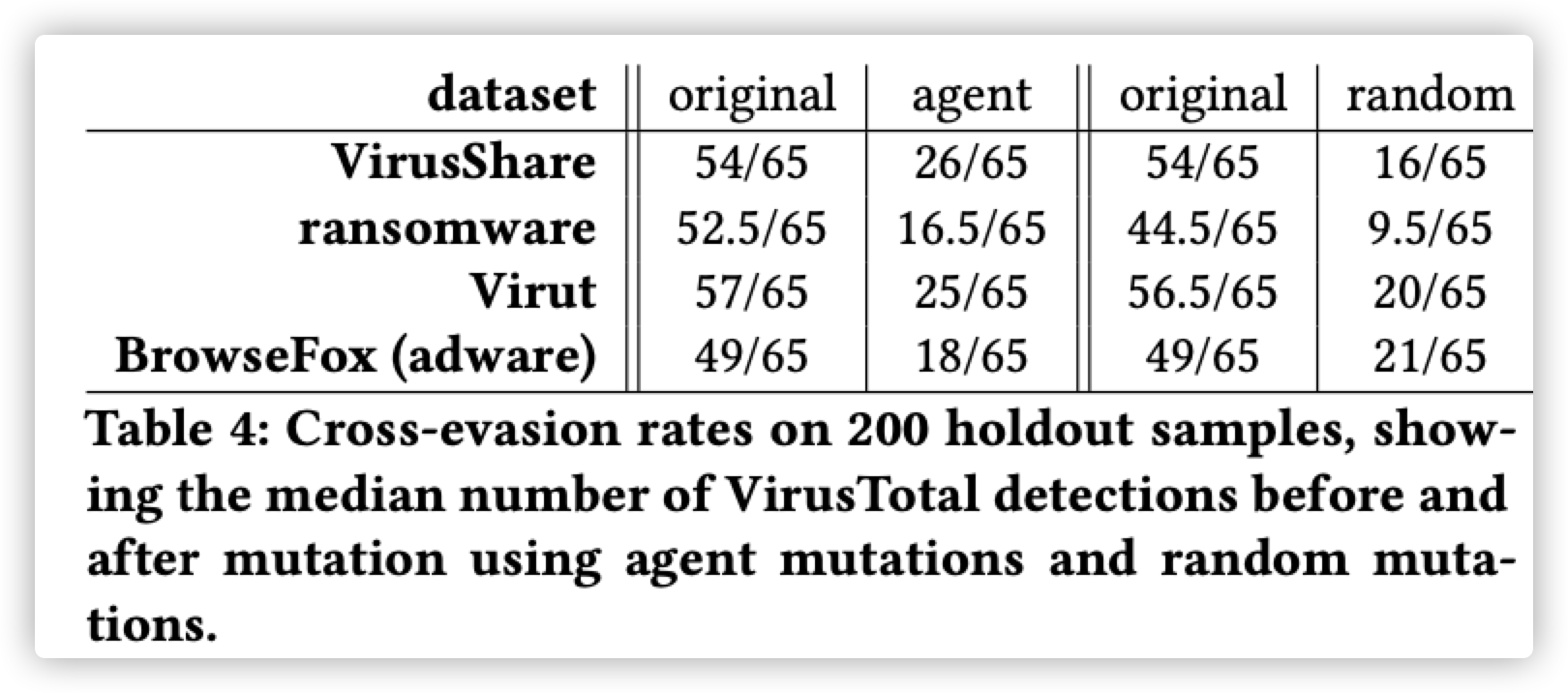
使用新生成的混淆样本来提升恶意软件的检测能力可行
在这里作者使用1543个ransomeware数据集中在agent训练过程中不能被原始的GBDT检测模型检测到的恶意软件样本,将其加入到训练集,对检测模型进行重训练,然后在使用之前训练好的强化学习代理对200个样本进行检测逃过尝试,发现逃逸成功率从12%下降到8%
简评
作者提出的强化学习方法基于已知的一些混淆方法,强化学习的作用只在于如何对混淆方法进行选择,让攻击者可以在更少的混淆尝试次数的前提下成功进行检测模型绕过,虽然模型相比随机选择绕过策略而言绕过成功率、成功绕过次数具有一定的优势,但是优势并不明显,虽然模型的训练时间作者并没有提及,众所周知强化学习的训练成本很高,因此模型是否有实际的使用价值值得商榷。