概述:浏览器编码解码顺序与利用这种机制进行xss bypass
三种不同编码方式
1. HTML编码(字符实体)
字符实体是一个预先定义好的转义序列。
字符实体两种表示方法:
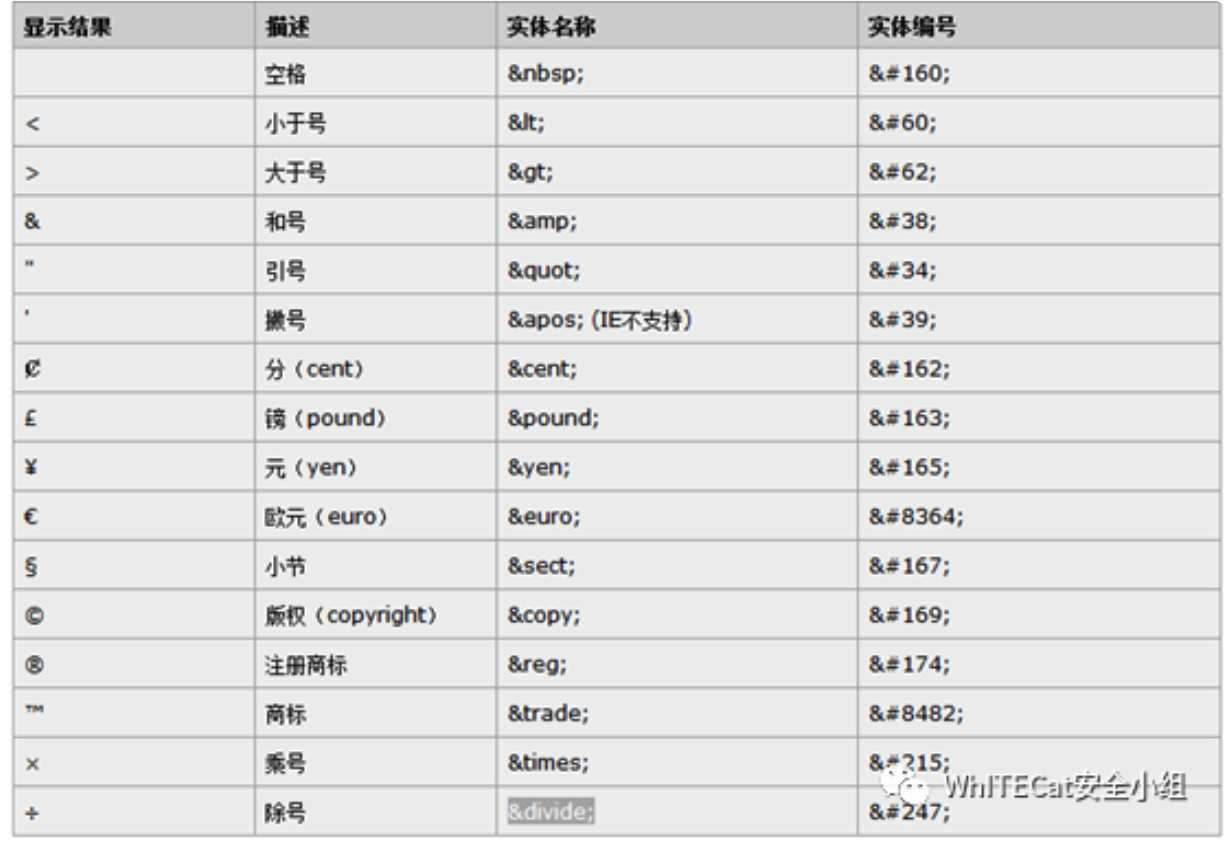
1、字符实体以&开头+预先定义的实体名称+;分号结束,如“<”的实体名称为<
2、字符实体还可以以&开头+#符号+字符在ASCII对应的十进制数字+;分号结束,如<的实体编号为<
字符都是有实体编号的,但有些字符是没有实体名称
2.JavaScript编码
最常用的,如\uXXXX这种写法的Unicode转义序列,表示一个字符,其中XXXX表示一个16进制数字,如<的Unicode编码为\u003c。
3.URL编码
RFC3986文档规定,URL中只允许包含英文字母(a-zA-Z)、数字(0-9)、-_.~4个特殊字符以及所有保留字符。
编码方式:%加字符在ASCII码表中的十六进制值。
例如,/在ASCII码表中十六进制为0x2f,那么它对应的URL编码为%2f。
RFC3986中指定了以下字符为保留字符:! * ‘ ( ) ; : @ & = + $ , / ? # [ ]
浏览器解码规则
浏览器无论什么情况都会遵守一个这样的解码规则:
1、HTML解析器对HTML文档进行解析,完成HTML解码并且创建DOM树
2、JavaScript 或者 CSS解析器对内联脚本进行解析,完成JS、CSS解码
3、URL解码会根据URL所在的顺序不同而在JS解码前或者解码后
不同位置解析顺序不同三种实例
类型1
1 | <a href="UserInput"></a> |
解析顺序:HTML解析->URL解析->JavaScript解析
在该类型中,首先由HTML解析器对UserInput部分进行字符实体解码;接着URL解析器对UserInput进行URL decode;如果URL的Scheme部分为javascript的话,JavaScript解析器会再对UserInput进行解码。
类型2
1 | <a href=# onclick="window.open('UserInput')"></a> |
解析顺序:HTML解析->JavaScript解析->URL解析
在该类型中,首先由HTML解析器对UserInput部分进行字符实体解码;接着由JavaScript解析器会再对onclick部分的JS进行解析并执行JS;执行JS后window.open(‘UserInput’)函数的参数会传入URL,所以再由URL解析器对UserInput部分进行解码
类型3:
1 | <a href="javascript:window.open('UserInput')"> |
解析顺序:HTML解析->URL解析->JavaScript解析->URL解析
该例子中,首先还是由HTML解析器对UserInput部分进行字符实体解码;接着由URL解析器解析href的属性值;然后由于Scheme为javascript,所以由JavaScript解析;解析执行JS后window.open(‘UserInput’)函数传入URL,所以再由URL解析器解析。
利用浏览器解析机制进行Xss Bypass
【参考文献】