概述:首页描述
DQN
DQN全称Deep Q-Learning Network,这种强化学习方式被提出是为了解决当Q-table中状态过多,导致整个Q-Table无法装入内存的问题,在DQN中采用了一个深度神经网络来对Q-Table进行拟合,具体来说就是:向神经网络中输入当前状态,输出为各种操作对应的概率值。
原论文: Playing atari with deep reinforcement learning
使用场景:状态无限、动作有限
核心思想:DQN的模型训练过程与Q Learning本质上相同,都是通过计算Q现实与Q估计的差值,进行反向传播,从而完成模型的训练过程。
DQN中的两个关键点
1. Experience Replay
在DQN中与之前的强化学习算法不同,DQN首先进行反复的实验,每一次实验的结果都是一个sample,每个sample都是一个四元组:当前状态、当前状态对应各种action的Q值、当前状态采取action的即时回报、下一状态各种action的Q值。将这些sample存储在Memory中,经过一定step以后,再从Memory中随机抽取Sample来进行反向传播,更新eval_net。
为什么要使用Experience Replay?
按照时间顺序生成的样本是有关系的,后一时刻的Sample中的内容会收到前一时刻的影响,因此很容易导致难以收敛的问题,因此使用Experience Replay进行先将之前的Sample进行存储下来,然后再对存储下来的样本进行随机采样,从而在一定程度上去除掉这种相关性,使网络更容易收敛。
但是,与之相伴,因为要存储一定的Memory才能进行随机采样更新网络,因此导致DQN训练只能offline,无法做到online训练。

2. Fixed Q-target
Fixed Q-target是另一种打乱sample之间相关性的策略,Fixed Q-target在 DQN 中使用到两个结构相同但参数不同的神经网络,分别称为eval_net和target_net, eval_net每次选择action后都会进行及时的反向传播,更新网络参数,代表最新状态下的预测值,而target_net各一段时间才将其参数与eval_net进行同步,代表一段时间以前的预测值。
eval_net: 样本采取每个action后会都反向传播更新网络参数,保持参数最新,代表了最新状态下的预测值
target_net: 不进行反向传播,每隔一定时间将网络参数与eval_net进行更新,代表了一段时间以前的预测值
为什么要使用Fixed Q-target?
Fixed Q-target策略使用两个独立的网络来表示Q现实与Q估计在一定程度上降低了二者之间的相关性,使网络出现震荡的可能性降低。
Note: Fixed Q-target并不是原始的DQN论文中提出来的,而是后来有研究者进行提出的,但是被广泛应用,现在一般认为的DQN都是使用Q-target的。
算法实现
DQN模型设计
由于DQN要使用的Fixed Q-target策略中需要创建两个结构完全相同的模型,因此这里需要首先建立一个DQN的辅助网络,该网络结构即为未来DQN中eval_net和target_net类的结构。具体的模型结构可以由用户进行自定义设计,这里以两层网络结构为例。
1
2
3
4
5
6
7
8
9
10
11
12
13
14# 定义Net类 (定义网络)
class Net(nn.Module):
def __init__(self,states_dim,n_actions): # 定义Net的一系列属性
super(Net, self).__init__()
self.fc1 = nn.Linear(states_dim, 50) # 权重初始化 (均值为0,方差为0.1的正态分布)
self.fc1.weight.data.normal_(0, 0.1)
self.out = nn.Linear(50, n_actions)
self.out.weight.data.normal_(0, 0.1) # 权重初始化 (均值为0,方差为0.1的正态分布)
def forward(self, x):
x = F.relu(self.fc1(x))
actions_value = self.out(x)
return actions_value整体上DQN模型的整体架构如下图所示:
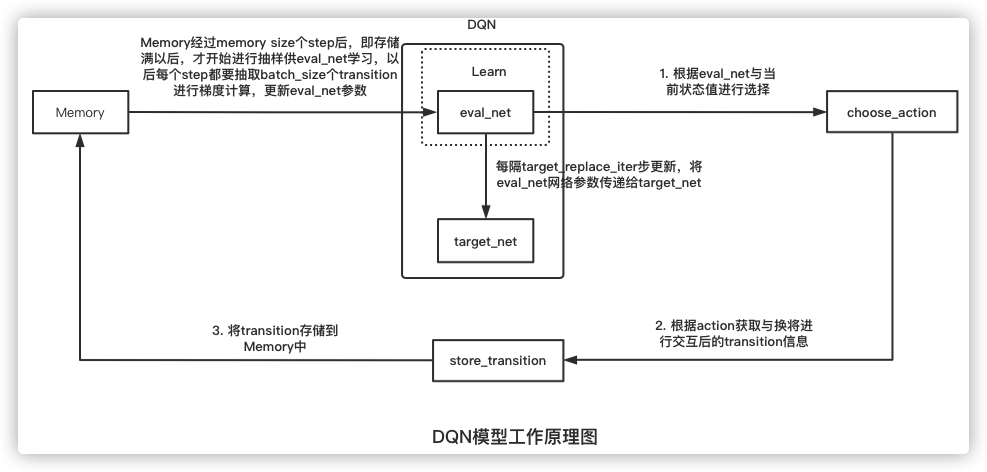
在图中可以看出,模型需要设置的参数包括:
- state_dim: 状态向量的维度,用于eval_net、target_net网络结构的创建
- action_nums: action的数量,用于eval_net、target_net网络结构的创建
- lr: eval_net进行梯度下降学习时的学习速率,用于learn阶段eval_net参数更新
- epsilon: 贪心算法系数,有epsilon的概率选择最优的action,有1-epsilon的概率随机进行选择,用于learn阶段eval_net参数更新
- gamma: 未来收益折现比率,用于learn阶段eval_net参数更新
- batch_size: 每次进行从Memory中抽取多少个sample更新eval_net,用于learn阶段eval_net参数更新
- memory_size: 记忆体的容量,用于确定经过多少step以后才开始更新eval_net
- target_replace_iter: 多久使用eval_net的参数替换一次target_net网络的参数,用于确定target_net网络更新频率
具体实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73# 定义DQN类 (定义两个网络)
class DQN(object):
def __init__(self,state_dim,n_actions,memory_size,epsilon,gamma,target_replace_iter,batch_size,lr):
self.state_dim = state_dim
self.n_actions = n_actions
self.epsilon = epsilon
self.gamma = gamma
self.memory_size = memory_size
self.target_replace_iter = target_replace_iter
self.batch_size = batch_size
self.eval_net, self.target_net = Net(state_dim,n_actions), Net(state_dim,n_actions)
self.learn_step_counter = 0 # 记录当前step数
self.memory_counter = 0 # 存储的记忆数量
self.memory = np.zeros((memory_size, state_dim * 2 + 2)) # 初始化记忆库,每行为一个transition
self.optimizer = torch.optim.Adam(self.eval_net.parameters(), lr=lr)
self.loss_func = nn.MSELoss()
def choose_action(self, obs):
"""
行为选择函数,根据当前obsversation进行action选择
"""
obs = torch.FloatTensor(obs)
if np.random.uniform() < self.epsilon: # 生成一个在[0, 1)内的随机数,如果小于EPSILON,选择最优动作,否则随机选择
actions_value = self.eval_net.forward(obs)
action = torch.max(actions_value, 1)[1].data.numpy() # 找出行为q值最大的索引,并转化为numpy数组
action = action[0]
else:
action = np.random.randint(0, self.n_actions)
return action
def store_transition(self, s, a, r, s_):
"""
记忆存储函数
"""
s,s_ = np.squeeze(s),np.squeeze(s_)
# 在水平方向上拼接数组
transition = np.hstack((s, [a, r], s_))
# 如果记忆库满了,便覆盖旧的数据
index = self.memory_counter % self.memory_size
self.memory[index, :] = transition
self.memory_counter += 1
def learn(self):
"""
学习函数,记忆库存储满后开始进行学习
"""
# 每隔target_replace_iter步后,target网络参数更新
if self.learn_step_counter % self.target_replace_iter == 0:
self.target_net.load_state_dict(self.eval_net.state_dict())
self.learn_step_counter += 1
# 抽取记忆库中的batch_size个记忆数据
sample_index = np.random.choice(self.memory_size, self.batch_size)
b_memory = self.memory[sample_index, :]
# 记忆数据中的state、action、reward、state_分开
b_s = torch.FloatTensor(b_memory[:, :self.state_dim])
b_a = torch.LongTensor(b_memory[:, self.state_dim:self.state_dim+1].astype(int))
b_r = torch.FloatTensor(b_memory[:, self.state_dim+1:self.state_dim+2])
b_s_ = torch.FloatTensor(b_memory[:, -self.state_dim:])
# 获取32个transition的评估值和目标值,并利用损失函数和优化器进行评估网络参数更新
q_eval = self.eval_net(b_s).gather(1, b_a) # eval_net(b_s)通过评估网络输出32行每个b_s对应的一系列动作值,然后.gather(1, b_a)代表对每行对应索引b_a的Q值提取进行聚合
q_next = self.target_net(b_s_).detach() # Note: q_next不进行反向传递误差,所以detach
q_target = b_r + self.gamma * q_next.max(1)[0].view(self.batch_size, 1) # q_next.max(1)[0]表示只返回每一行的最大值,不返回索引(长度为32的一维张量);.view()表示把前面所得到的一维张量变成(BATCH_SIZE, 1)的形状;最终通过公式得到目标值
loss = self.loss_func(q_eval, q_target)
# 输入32个评估值和32个目标值,使用均方损失函数
self.optimizer.zero_grad() # 清空上一步的残余更新参数值
loss.backward() # 误差反向传播, 计算参数更新值
self.optimizer.step() # 更新评估网络的所有参数模型训练与测试
DQN模型的使用与一般地RL模型的差异不大,只是不再进行每个episode都要进行模型参数的更新,而是先将其组成transition存储在Memory中。下面一个在有限次数进行逃逸的具体代码实现,其中参数包括:
epoch: 独立重复试验的次数, 由于强化学习具有一定的偶然性,因此一般使用多次重复独立实验
episode: 每次独立重复试验中在训练集中随机抽取多少次样本进行完整的强化学习过程(循环执行多个action,直至达到最大action次数或者奖励阈值)
max_episode_steps: 一次episode中最多能进行的action次数
具体代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35# 模型训练参数设置
epoch = 5 # 进行实验的次数,因为强化学习具有一定的随机性,因此一般都需要多次独立重复实验
episode = 10000 # 每次独立重复实验重复的选择随机选择样本进行强化学习的次数
max_episode_steps = 5 # 对每个样本最多能够进行action操作的步数
sum_evasion = 0
for epoch in range(epoch):
# DQN模型声明
dqn = DQN(STATES_DIM,N_ACTIONS,MEMORY_CAPACITY,EPSILON,GAMMA,TARGET_REPLACE_ITER,BATCH_SIZE,LR)
# 模型训练
for i in range(episode): # 使用的训练样本数
s = env.reset() # 重置环境
episode_reward_sum = 0 # 初始化该循环对应的episode的总奖励
step = 0
done = False
# 样本成功完成任务或到达可走最大step结束循环
while not done or step<max_episode_steps:
step += 1
a = dqn.choose_action(s) # 输入该步对应的状态s,选择动作
s_, r, done, info = env.step(a) # 执行动作,获得反馈
dqn.store_transition(s, a, r, s_) # 存储样本
episode_reward_sum += r # 逐步加上一个episode内每个step的reward
s = s_ # 更新状态
if dqn.memory_counter > MEMORY_CAPACITY: # Note:如果累计的transition数量超过了记忆库的固定容量2000
dqn.learn() # 学习,在记忆中随机抽取batch_size个样本,更新eval_net网络参数,eval_net每更新100次以后将其参数跟新到target_net
# 效果测试
sum,success = rl_test()
sum_evasion += success
print("测试样本总数:{}, 成功绕过数:{}".format(sum,sum_evasion/n))