概述:首页描述
概述
原文链接:https://dl.acm.org/doi/abs/10.1145/3290480.3290494
攻击目标:静态可执行文件检测引擎
方法:强化学习,通过设计一些类的混淆策略,让代理与检测引擎进行一些列的交互以后,RL模型可以学习到对于任何给定的模型都给出可以绕过静态检测引擎的检测。
模型输出:可以逃逸静态模型(黑盒测试)检测的恶意软件
特征提取工具:LIEF库
这篇文章的工作主要是基于gym-mal论文的基础上进行的进一步研究
创新点:
- 新增新增了actions的,修改了Agent具体RL模型提高了使用RL生成的恶意样本逃逸率
- PE头时间戳修改
- 修改可选头中一些不重要的符号,例如图片次要版本等
- 修改节中原始数据的大小
- 重新排序PE文件中的一些资源(重排不影响效果的重要资源)
- 新增了重训练流程,将RL生成的可逃逸原始检测模型的样本作为新的训练集样本添加到训练集中,提升了检测模型的检测率
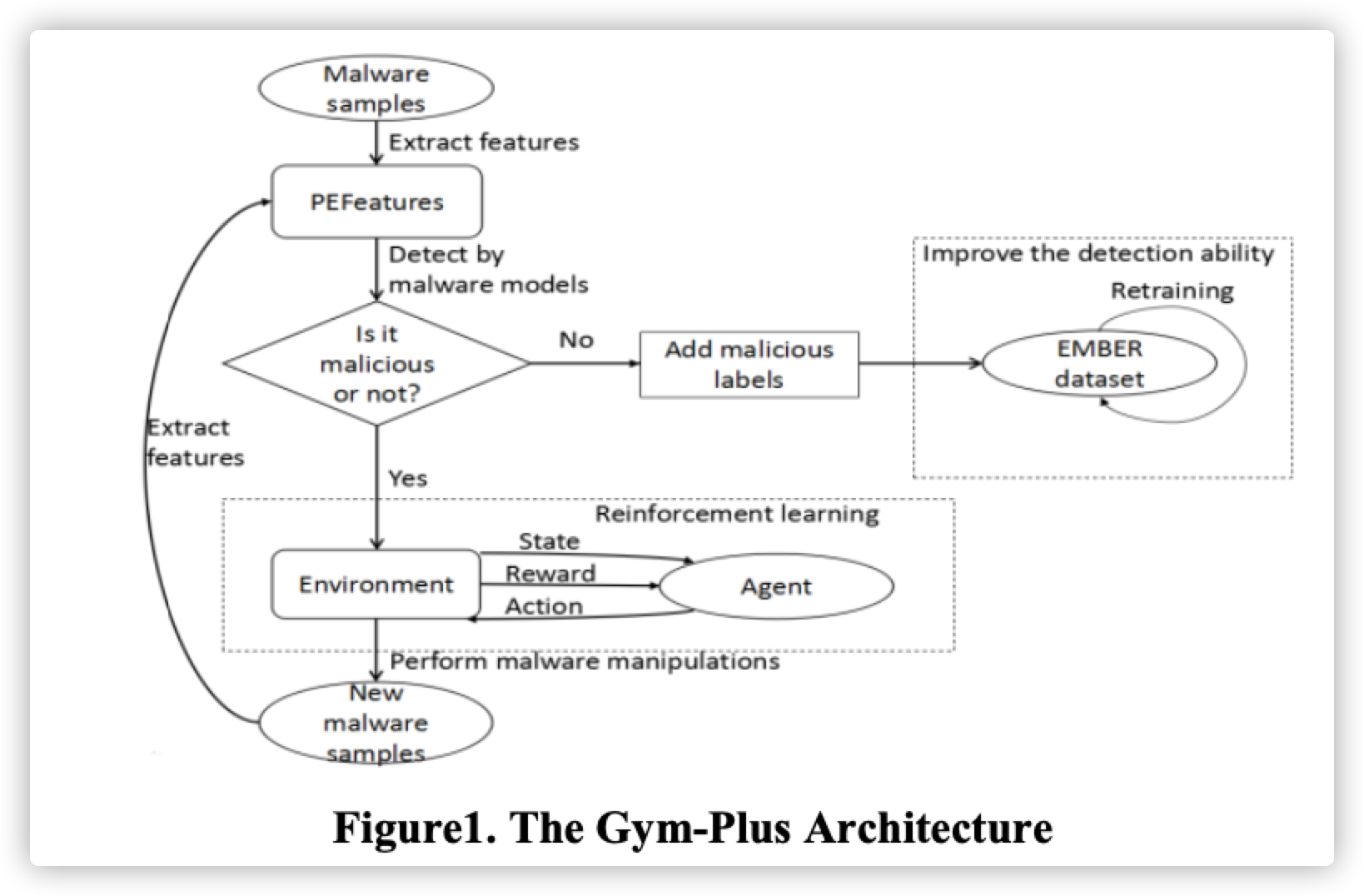
实验结果
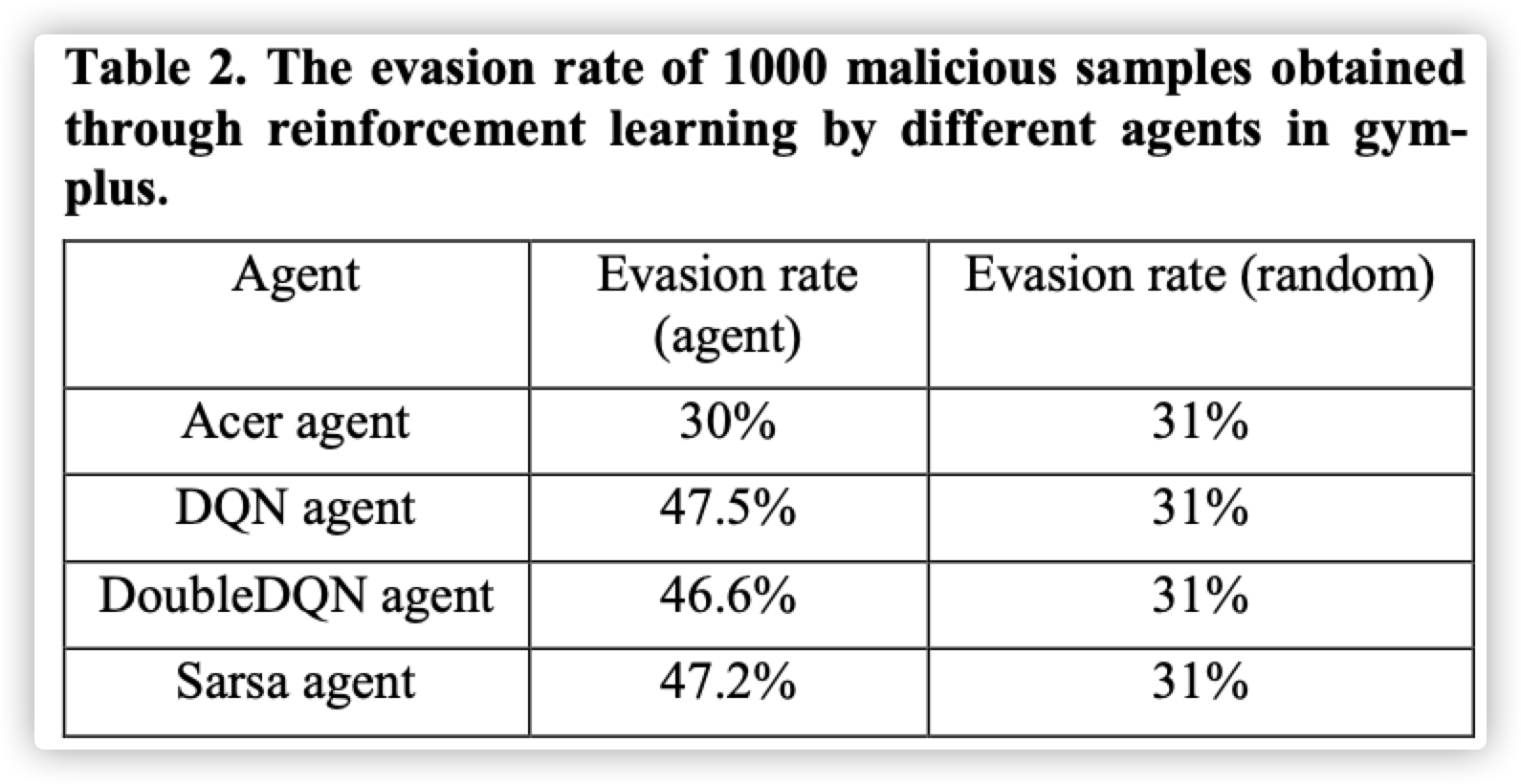
新加入action后,RL在10次变异内产生可以逃逸检测的成功率上升30%
这里我认为更有意义的结论应该是随着action数量的增加,使用RL进行逃逸的成功率与随机逃逸的成功率差距越来越明显。
在gym-mal的实验中,RL与随机的逃逸成功率差距只有1.4%,使用强化学习进行恶意软件混淆的优越性并没有体现出来,而在增加action以后的gym-plus中,RL与随机进行逃逸的成功率差距则上升到了16%,上升了10倍有余,切实的说明了使用RL进行恶意软件混淆的必要性

Agent具体的强化学习模型算法的算法选择很重要
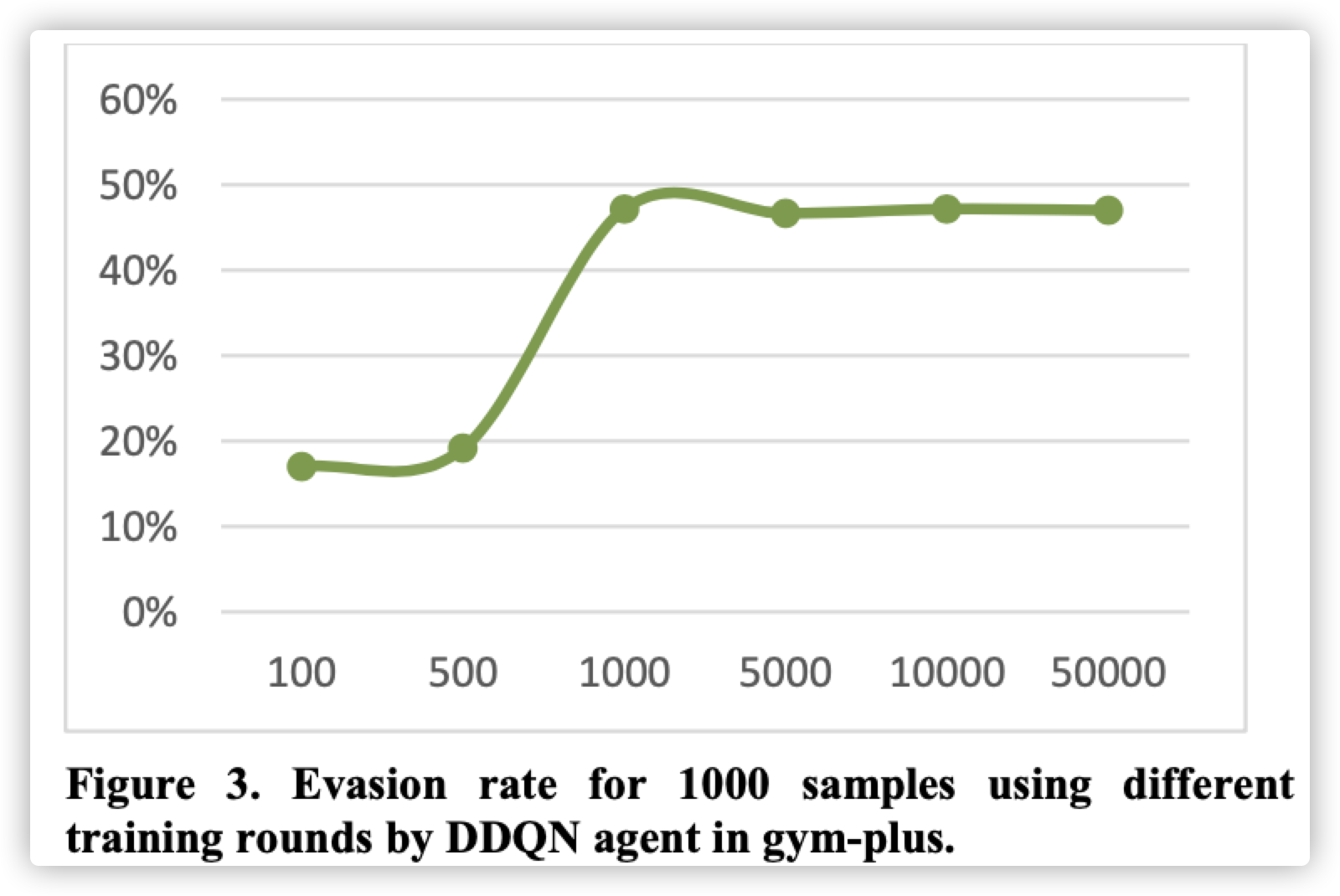
逃逸成功率并不是一直随着训练轮数的增加而增加的,训练达到1000轮后会趋于稳定
使用gym-plus生成的对抗样本进行对抗性训练对原始的检测模型对新的混淆样本检测能力提升明显

简评
本篇论文主要是基于gym-mal论文的进一步研究,没有特别的技术创新,主要贡献在于action的丰富与对比实验,进一步证明了使用强化学习进行绕过恶意软件检测与随机混淆绕过的优势,同时也证明了使用RL生成的混淆样本提升恶意软件模型的检测能力的可行性。
参考文献
- xxx
- xxx