Attention
参考阅读:
1.为什么要使用Attention机制?
Attention机制最初起源于seq2seq中,经典的encoder-decoder做机器翻译时,通常是是使用两个RNN网络,一个用来将待翻译语句进行编码输出一个vector,另一个RNN对上一个RNN网络的输出进行解码,也就是翻译的过程。但是经典的encoder-decoder模式最大的缺点在于:不管输入多么长的语句,最后输出的也只是最后一个vector,这个向量能否有效的表达该语句非常值得怀疑,而Attention机制正是利用了RNN整个过程中的各个输出来综合进行编码
原始序列模型的不足:
1.从编码器到解码器的语境矩阵式大小是固定的,这是个瓶颈问题
2.难以对长的序列编码,并且难以回忆长期依赖
2. Attention原理
第一步: query 和 key 进行相似度计算,得到权值
第二步:将权值进行归一化,得到直接可用的权重
第三步:将权重和 value 进行加权求和
3. Attention有哪几种常见的类型
RNN Attention: 最早提出的attention类型,基于encoder-decoder框架
纯Attention:最早由transformer提出的self-attention就是纯attention,摒弃了循环结构,使下一时刻的输入不在依赖于上一时刻的输出,使其可以进行并行化
RNN Attention
1.首先在RNN的过程中保存每个RNN单元的隐藏状态(h1….hn)
2.对于decoder的每一个时刻t,因为此时有decoder的输入和上一时刻的输出,所以我们可以的当前步的隐藏状态St
3.在每个t时刻用St和hi进行点积得到attention score

4.利用softmax函数将attention score转化为概率分布
利用下面的公式进行概率分布的计算:


5.利用刚才的计算额Attention值对encoder的hi进行加权求和,得到decoder t时刻的注意力向量(也叫上下文向量)


6.最后将注意力向量和decoder t时刻的隐藏状态st并联起来做后续步骤(例如全连接进行分类)

self-attention
核心思想:根据本句话,获取本句话各个单词的注意力权重(不再需要根据前一时刻预测后一时刻)
优势:计算效率更高,可并行化
缺陷:对当前位进行编码时,会将注意力过度集中于自身位置
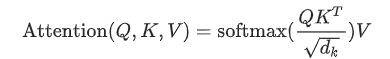
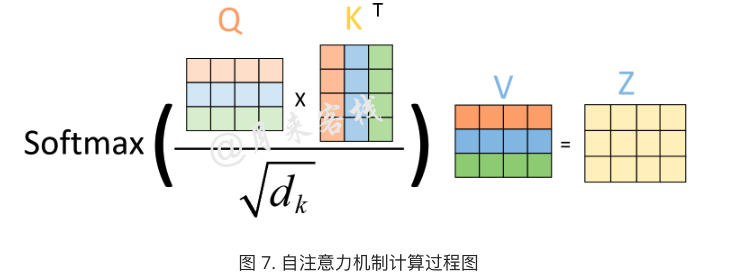
由句子的原始向量表示经三个线性变化获得query、key、value表示
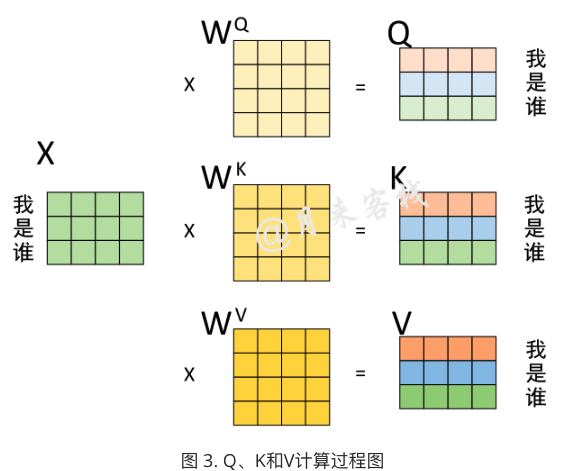
计算注意力权重矩阵
其中除了矩阵相乘后,还进行缩放与softmax概率归一化,未在图中进行展示,实际过程如下图所示:
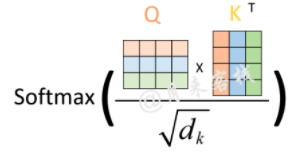
其中$d_k$为key的embedding向量大小。
缩放这一步是因为通过实验作者发现,对于较大的来说在完成后将会得到很大的值,而这将导致在经过sofrmax操作后产生非常小的梯度,不利于网络的训练。
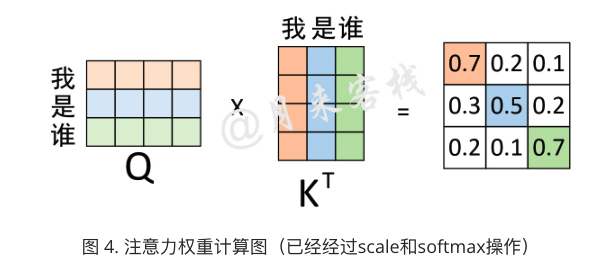
将注意力权重矩阵作用于value矩阵

权重矩阵含义:
0.3表示的就是“我”与”是”的注意力值;0.5表示的就是“是”与”是”的注意力值;0.2表示的就是“谁”与”谁”的注意力值。换句话说,在对序列中的”是“进行编码时,应该将0.3的注意力放在”我“上,0.5的注意力放在”是“上,将0.2的注意力放在“谁”上。

3.Attention计算方式
前面一节中,我们的概率分布来自于h与s的点积再做softmax,这只是最基本的方式。在实际中,我们可以有不同的方法来产生这个概率分布,每一种方法都代表了一种具体的Attention机制。在各个attention中,attention的计算方式主要有加法attention和乘法attention两种。
3.1 加法attention
在加法attention中我们不在使用st和hi的点乘,而是使用如下计算:

其中,va和Wa都是可以训练的参数。使用这种方式产生的数在送往softmax来进行概率分布计算
3.2 乘法attention
在乘法attention中使用h和s做点乘运算:

显然乘法attention的参数更少,计算效率更高。
4.self-attention
思想:在没有任何额外信息情况下,句子使用self-attention机制来处理自己,提取关键信息
在attention机制中经常出现的一种叫法:
query:在一个时刻不停地要被查询的那个向量(前面的decodert时刻的隐藏状态st)。
key: 要去查询query计算个query相似关度的向量(前面的encoder在各个时刻的隐藏状态hi)
value: 和softmax得到的概率分布相乘得到最终attention上下文向量的向量(前面的encoder在各个时刻的隐藏状态hi)
这里我们可以明显知道,任意attention中key和value是相同的
attention就是key、value、和query都来自同一输入的(也是相同的)