Transformer
推荐阅读:
- This post is all you need(①多头注意力机制原理)
- This post is all you need(②位置编码与编码解码过程)
为什么要引入Positional Embedding?Transformer是怎么实现的?
简述Transformer的模型的结构
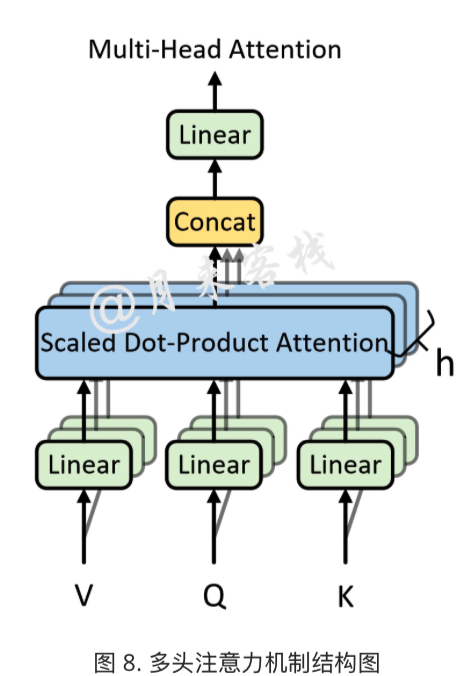
什么是Muti-head Atttention?为什么要使用?
作用:
- 解决self-attention在对当前位置的信息进行编码时,会过度将注意力集中与自身位置的问题。
- 给与注意力层的输出包含有不同子空间中的编码表示信息,从而增强模型的表达能力。
Muti-head Attention:
将原始的输入序列进行多组的自注意力处理过程,然后再将每一组自注意力的结果拼接起来进行一次线性变换得到最终的输出结果。
Transformer在训练时解码器的输入是怎么样的?为何采用这种方式?
在真实预测时,解码器需要将上一时刻的输出作为下一时刻解码器的输入,然后一个时刻一个时刻的进行解码操作,但是在训练时并没有采用这样的方式一个时刻一个时刻的进行预测,而是与编码器一致,直接一次性将解码时所有时刻进行运算。
好处:
- 多样本并行计算能够加快网络的训练速度
- 训练过程中直接为入解码器的正确结果而不是上一时刻的预测值能够很好的训练网络
Transformer中几次用到掩码机制?分别有什么作用?
transformer中共用到下面两次掩码机制:
Attention Mask:用于在训过程中解码的时候掩盖掉当前时刻之后的信息。
虽然为了加速训练效率,正要进行解码的全部时刻同时输入了解码器,但在实际预测过程中依旧应该遵循:使用当前时刻之前(包括当前时刻)的所有时刻来预测下一时刻,也就是说模型在预测时不应该看到当前时刻之后的信息,因此引入Attention Mask来解决这一问题。
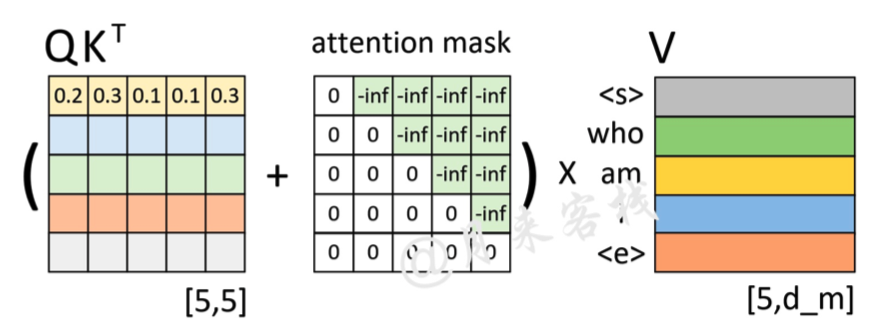
如上图所示,左边依旧是通过Q和K计算得到了注意力权重矩阵(此时还未进行softmax操作),而中间的就是所谓的注意力掩码矩阵,两者在相加之后再乘上矩阵V便得到了整个自注意力机制的输出。以图中第1行权重为例,当解码器对第1个时刻进行解码时其对应的输入只有'< s >',因此这就意味着此时应该将所有的注意力放在第1个位置上,换句话说也就是第1个位置上的权重应该是1,而其它位置则是0。
Padding Mask:对不同长度的padding成相同长度的序列,对padding部分的信息进行掩盖。
由于在网络的训练过程中同一个batch会包含有多个文本序列,而不同的序列长度并不一致。因此在数据集的生成过程中,就需要将同一个batch中的序列Padding到相同的长度。但是,这样就会导致在注意力的计算过程中会考虑到Padding位置上的信息
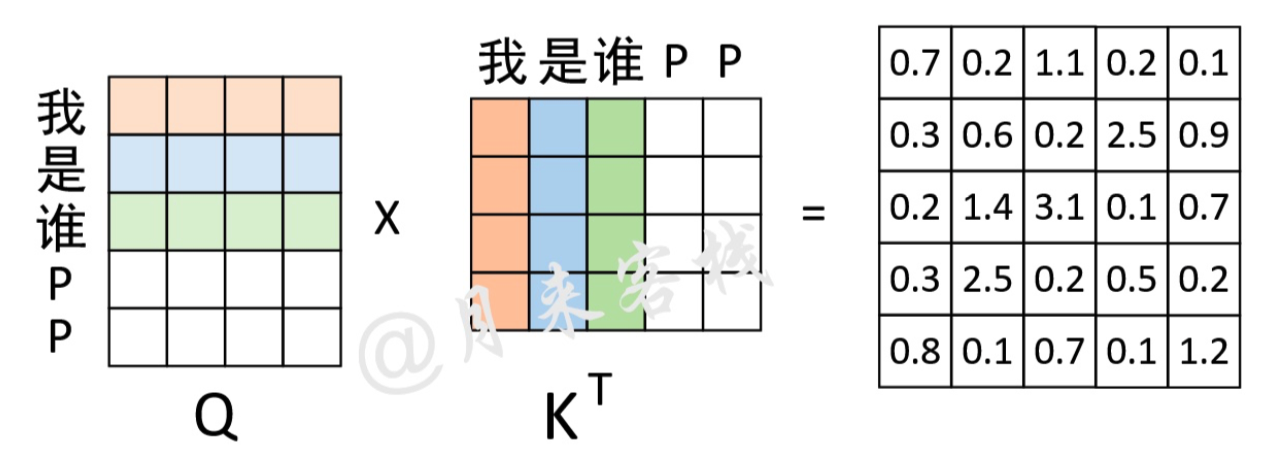
如上图所示,P表示Padding的位置,右边的矩阵表示计算得到的注意力权重矩阵。可以看到,此时的注意力权重对于Padding位置山的信息也会加以考虑。因此在Transformer中,作者通过在生成训练集的过程中记录下每个样本Padding的实际位置;然后再将注意力权重矩阵中对应位置的权重替换成负无穷便达到了忽略Padding位置信息的目的。这种做法也是Encoder-Decoder网络结构中通用的一种办法。
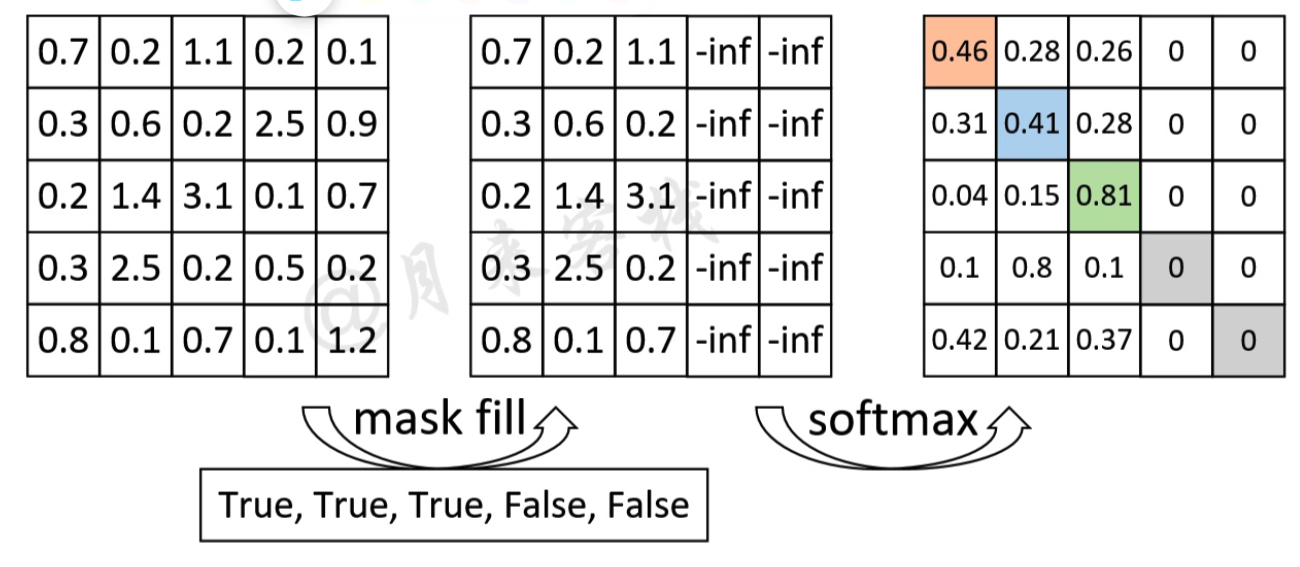
如上图所示,对于”我 是 谁 P P“这个序列来说,前3个字符是正常的,后2个字符是Padding后的结果。因此,其Mask向量便为
[True, True, True, False, False]。通过这个Mask向量可知,需要将权重矩阵的最后两列替换成负无穷,在后续我们会通过torch.masked_fill这个方法来完成这一步,并且在实现时将使用key_padding_mask来指代这一向量。