BERT
推荐阅读:
1. 简述BERT模型的基本结构
BERT的整体结构:Embedding+Transformer Encoder
输入:每次输入为两句话,通过[SEP]分隔符隔开
结构:
Embedding
组成:word embedding(无预训练) + position embedding + segment embedding

Transformer Encoder
Transformer Encoder由N个Transformer block组成,每个block可以分为输入和输出两部分,每一部分都按照sublayer的标准结构组成:
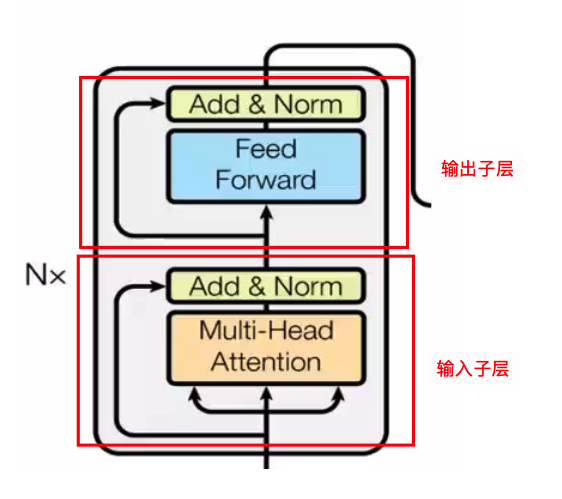
输入子层
输入子层中核心为Muti-Head Attention,在其上加入了Norm、残差连接、dropout机制。
输出子层
输出子层中sulayer为Feed Forward,在其上加入了Norm、残差连接、dropout机制。
Feed Forward结构:
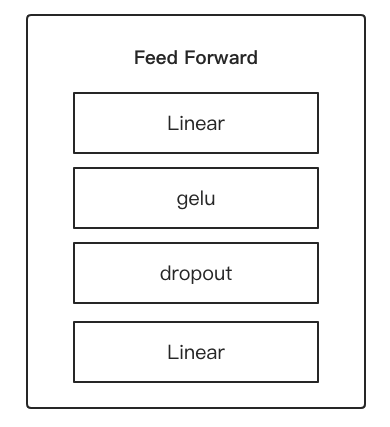
Sublayer结构
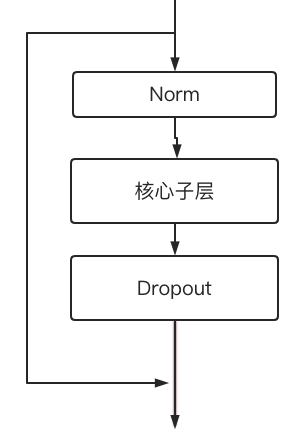
输入子层与输出子层都遵循下面的结构,其中Muti-Head Attention、Feed Forward即为其中的核心子层.
2. BERT如何进行训练?Loss如何构成?
BERT的训练任务:Mask Language Model(MLM)+Next Sentence Predict(NSP)
Mask Language Model(MLM)
目标:根据上下文预测当前词(只预测mask的词)
样本生成:随机选择15%的词进行随机token mask,这15%中10%不替换,10%采用随机词进行替换,80%采用[MASK]标记进行替换
在token mask中加入了随机化操作目的是为了减小mask对模型的影响,mask只会在训练时出现,在预测时并不会出现mask
Next Sentence Predict(NSP)
目标:预测第二条句子是否为第一条句子的后续句子(以[SEP]标记分割)
样本生成:从语料库中相邻的句子对中,随机选择50%的样本将第二条句子进行随机替换,替换后的样本为负样本,未进行替换的50%样本为正样本
在BERT中的Embedding+Transformer Encoder主结构后,将输出向量用两个全连接网络进行MLM和NSP任务的预测
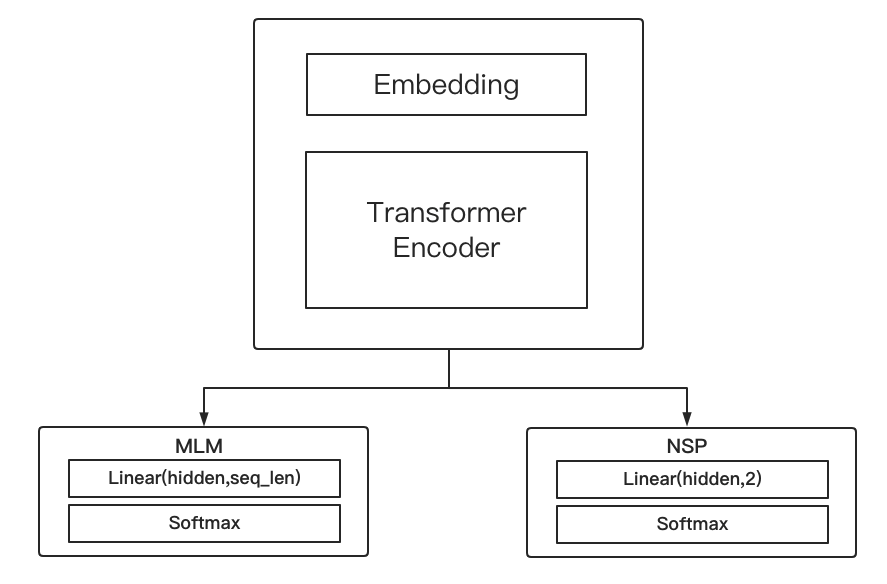
Loss构成:MLM Loss+NSP Loss
3. 什么是Muti-Head Attention?有什么作用?
作用:
- 解决self-attention在进行词向量表示过于将注意力集中于自身的问题
- 使词向量包含不同子空间中的编码表示信息,增强模型表达能力
结构:
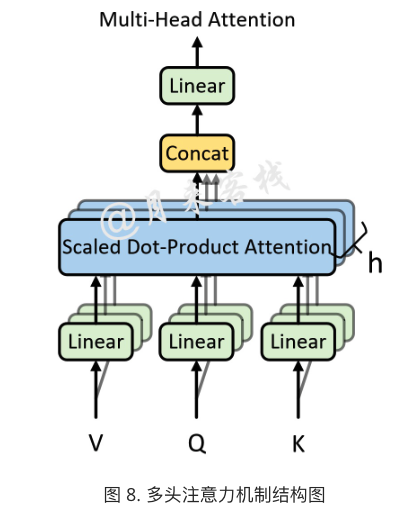
所谓的多头注意力机制其实就是将原始的输入序列进行多组的自注意力处理过程;然后再将每一组自注意力的结果拼接起来进行一次线性变换得到最终的输出结果。
本质:将一个高维self-attention head拆分成多个self-atteion head,每个头的输入维度为$d{model}/head{nums}$
4.BERT为代表的的语言模型和word2vec为代表的词向量模型在进行文本表征任务时有什么区别?
最大的区别:词向量模型无法处理同义词的问题。
词向量模型当前词表示过于依赖上下文N个词的共现关系,而这种关系只是短程依赖,很多时候不能完整的表达出词语的语义信息。
例如:两句话中特朗普和川普,表示相同的语义,但依照词向量的建模方法,他们拥有不同的上下文,就会有不同的词向量
美国总统特朗普决定再墨西哥边境修建隔离墙
听说美国那个川普要在墨西哥边境修建隔离墙
5. BERT与transformer有哪些异同点?
相同点:
- Bert的网络结构就是基于transformer的,在网络结构上基本一致
不同点:
- 输入编码不同
- transformer的编码采用Token Embedding+Positional Embedding,Bert编码采用Token Embedding+Positional Embeddin+Segment Embedding(用于区分不同序列)。
- transformer的Positional Embedding采用固定的三角函数转换公式进行编码,Bert的Positional embedding则采用词嵌入的方式为每个位置初始化一个向量,然后随着网络一起训练
- 网络结构不同
- bert基于transformer但其中只使用了transformer中的Embedding和transformer encoder部分,并且加入了两个预测任务网络
- 训练任务不同
- transformer 翻译任务
- Bert在训练过程中引入两个训练任务:
- MLM
- NSP
6. BERT中的token mask与Cbow有什么异同点?
相同点:两种方式都采用了使用一个词周围词去预测其自身的模式。
不同点:
mask ml是应用在多层的bert中,用来防止 transformer 的全局双向 self-attention所造成的信息泄露的问题;而Cbow时使用在单层的word2vec中,虽然也是双向,但并不存在该问题
cbow会将语料库中的每个词都预测一遍,而mask ml只会预测其中的15%的被mask掉的词
7. BERT如何获得句子的向量表示?
使用倒数第二层Transformer的句子中起始的[CLS]作为当前句子的向量表示。
训练时各项训练任务依旧使用最后一层Transformer作为BERT各项训练任务的输入。因此要进行线上部署时需要注意去掉训练好的模型最后一个Transformer后重新保存模型作为线上embedding模型。