word2vec
推荐阅读:
word2vec
1. word2vec原理是什么?简要描述一下?
Word2Vec 的训练模型本质上是只具有一个隐含层的神经元网络(如下图)。
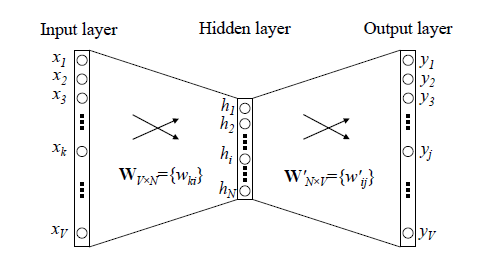
输入:One-Hot编码的词汇表向量
输出:One-Hot编码的词汇表向量
使用所有的样本,训练这个神经元网络,等到收敛之后,从输入层到隐含层的那些权重,便是每一个词的采用Distributed Representation的词向量。比如,上图中单词的Word embedding后的向量便是矩阵 的第i行的转置。这样我们就把原本维数为V的词向量变成了维数为N的词向量(N远小于V),并且词向量间保留了一定的相关关系。
2. word2vec是如何进行训练的?
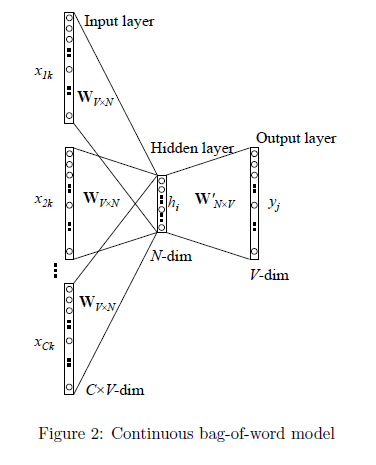
1、输入层:上下文单词的One-Hot编码词向量,V为词汇表单词个数,C为上下文单词个数。以上文那句话为例,这里C=4,所以模型的输入是(is,an,on,the)4个单词的One-Hot编码词向量。
2、初始化一个权重矩阵 ,然后用所有输入的One-Hot编码词向量左乘该矩阵,得到维数为N的向量
,这里的N由自己根据任务需要设置。
3、将所得的向量 相加求平均作为隐藏层向量h。
4、初始化另一个权重矩阵 ,用隐藏层向量h左乘
,再经激活函数处理得到V维的向量y,y的每一个元素代表相对应的每个单词的概率分布。
5、y中概率最大的元素所指示的单词为预测出的中间词(target word)与true label的One-Hot编码词向量做比较,误差越小越好(根据误差更新两个权重矩阵)
在训练前需要定义好损失函数(一般为交叉熵代价函数),采用梯度下降算法更新W和W'。训练完毕后,输入层的每个单词与矩阵W相乘得到的向量的就是我们想要的Distributed Representation表示的词向量,也叫做word embedding。因为One-Hot编码词向量中只有一个元素为1,其他都为0,所以第i个词向量乘以矩阵W得到的就是矩阵的第i行,所以这个矩阵也叫做look up table,有了look up table就可以免去训练过程,直接查表得到单词的词向量了。
3. word2vec有哪两种?分别有什么特点?
(1) cbow的速度更快,时间复杂度为O(V),skip-gram速度慢,时间复杂度为O(nV)
在cbow方法中,是用周围词预测中心词,从而利用中心词的预测结果情况,使用GradientDesent方法,不断的去调整周围词的向量。cbow预测行为的次数跟整个文本的词数几乎是相等的(每次预测行为才会进行一次backpropgation, 而往往这也是最耗时的部分),复杂度大概是O(V);
而skip-gram是用中心词来预测周围的词。在skip-gram中,会利用周围的词的预测结果情况,使用GradientDecent来不断的调整中心词的词向量,最终所有的文本遍历完毕之后,也就得到了文本所有词的词向量。可以看出,skip-gram进行预测的次数是要多于cbow的:因为每个词在作为中心词时,都要使用周围每个词进行预测一次。这样相当于比cbow的方法多进行了K次(假设K为窗口大小),因此时间的复杂度为O(KV),训练时间要比cbow要长。
(2)当数据较少或生僻词较多时,skip-gram会更加准确;
在skip-gram当中,每个词都要收到周围的词的影响,每个词在作为中心词的时候,都要进行K次的预测、调整。因此, 当数据量较少,或者词为生僻词出现次数较少时, 这种多次的调整会使得词向量相对的更加准确。因为尽管cbow从另外一个角度来说,某个词也是会受到多次周围词的影响(多次将其包含在内的窗口移动),进行词向量的跳帧,但是他的调整是跟周围的词一起调整的,grad的值会平均分到该词上, 相当于该生僻词没有收到专门的训练,它只是沾了周围词的光而已。
4. word2vec有哪两种优化措施?分别解决了什么问题?
Hierarchical softmax:Hierarchical Softmax对原模型的改进主要有两点,1. 从输入层到隐藏层的映射,没有采用原先的与矩阵W相乘然后相加求平均的方法,而是直接对所有输入的词向量求和。假设输入的词向量为(0,1,0,0)和(0,0,0,1),那么隐藏层的向量为(0,1,0,1)。 2. 采用哈夫曼树来替换了原先的从隐藏层到输出层的矩阵W’。哈夫曼树的叶节点个数为词汇表的单词个数V,一个叶节点代表一个单词,而从根节点到该叶节点的路径确定了这个单词最终输出的词向量。
优点:
1.由于是二叉树,之前计算量为V,现在变成了log2V,效率更高
2.由于使用霍夫曼树是高频的词靠近树根,这样高频词需要更少的时间会被找到。
缺点:
对于生僻词在hierarchical softmax中依旧需要向下走很久
Negative Sampling: 随机选择一个较少数目(比如说5个)的“负”样本来更新对应的权重。(在这个条件下,“负”单词就是我们希望神经网络输出为0的神经元对应的单词)。并且我们仍然为我们的“正”单词更新对应的权重(也就是当前样本下”quick”对应的神经元仍然输出为1)
优点:
1.对于低频词的计算效率依然很高
doc2vec
1. Doc2vec原理
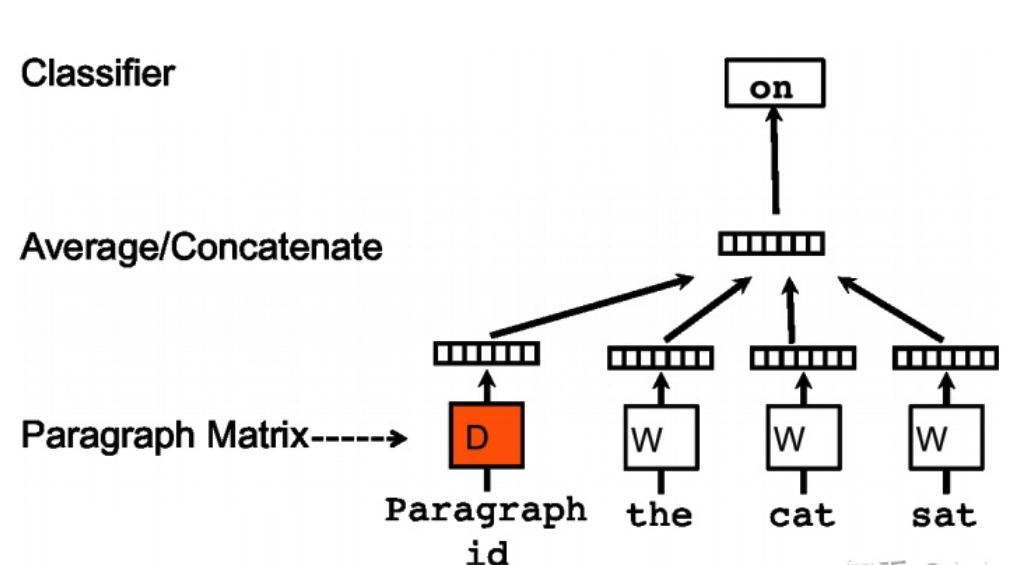
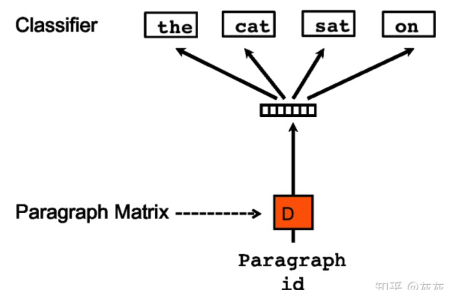
doc2vec与word2vec的不同点:在输入层增加了Paragraph id向量,来作为句子的表示向量,该向量在同一句子的不同词训练中是权值共享的
原因:在word2vec训练中,每次只会选择句子中窗口内的词来进行训练学习当前词的向量表达,而忽略了窗口外的词,,而Doc2vec中加入Paragraph id作为记忆的角色,加入Paragraph id向量在同一个句子的若干次训练中是共享的,所以同一句话会有多次训练,每次训练中输入都包含Paragraph vector,它可以被看作是句子的主旨,这样训练在获得词向量的同时也能获得准确的句子向量表示。
2. Doc2vec结构
Doc2Vec核心结构主要为三个全连接层(权重矩阵)、一个平均或加和操作和一个softmax层。
三个权重矩阵分别为:
- 段落向量矩阵:用于获取当前段落的向量表示,格式为:(段落数量,段落向量大小)
- 词向量矩阵:用于获取每个单词的向量表示,形状为:(词汇表中词汇数量,词向量大小)
- 隐藏层到输出层的权重矩阵:用于将隐藏层向量转化为输出层的向量表示经过softmax获得预测词
注意:
- 在Doc2vec中段落向量大小与词向量大小要保持一致,因为后面需要二者进行累加或者平均操作
- 在预测阶段,段落向量矩阵和词向量矩阵在都会进行固定,只有隐藏层到输出层的权重矩阵进行更新
隐藏层向量获取操作:平均或加和,将输入层输入的段落向量表示和采样到的词汇向量表示聚合为隐藏层的向量表示
softmax层:通过输出层的向量表示预测当前词
3. Doc2vec如何进行训练和预测?
训练:
- 每次从一句话中滑动采样固定长度的词,取其中一个词作预测词,其他的作输入词。
- 输入词对应的词向量和本句话对应的句子向量Paragraph vector作为输入层的输入,将本句话的句子向量和本次采样的词向量相加求平均或者累加构成一个新的向量X。
- 使用词向量X预测此次窗口内的预测词(softmax)
预测:
- 首先将新句子对应的Paragraph vector随机初始化,
- 固定词向量还有投影层到输出层的softmax weights参数,对句子中的单词进行预测,根据结果进行Paragraph vector更新,获得最终的Paragraph vector。
- 利用最终Paragraph vector进行词向量预测。
Doc2vec在进行预测时,需要重新进行训练,但是这个训练只是学习Paragraph vector,其他参数都被固定,因此会比训练阶段快很多
4. Doc2vec有哪几种训练方式?
Doc2vec与word2vec一样有两种形式:
PV-DM:类似于cbow,使用周围词预测当前词
PV-DMOW:类似于skip-gram,使用当前词预测周围词
4. word2vec有哪些缺陷,doc2vec弥补了哪些缺陷?
Word2vec缺陷:
- 语义信息中不包含顺序信息
- 只能包含局部窗口内的语义信息
doc2vec主要为了解决word2vec只包含局部窗口内的语义信息的问题,在进行词向量表示的时候融入了句子的语义表示。
Word2vec与doc2vec相比的优势在于使用方便,速度更快。doc2vec预测阶段仍要仍要对Paragraph vector进行训练后进行词向量的预测,而word2vec则可以直接进行预测
5. Doc2vec如何进行使用
目前常见的的使用方法有两种:
- 语义向量表示,这种使用方式与word2vec场景完全一致,只是当做融入句子语义的word2vec。
- 文章向量表示:在预测阶段,使用训练好的Paragraph vector作为句子/文章的向量表示,用于文章分类或文章相似度分析等任务。